图像分类相关模型复现手记
📖 阅读信息
阅读时间约 128 分钟 | 约 13908 字 ⚠️ 万字长文,请慢慢阅读 | 约 223 个公式 | 约 3656 行代码
这是模型复现手记的第一篇,主要挑几个经典或者邪门的图像分类模型进行复现。相关模型的架构和理论在网上都有诸多的讨论了,本文就仅做简单的推导而已。
前面的 MLP, CNN, ResNet, ViT 都是经典的图像分类模型,后面准备介绍的是几个邪门的模型,即参考 ViT 思想的 Patch based LSTM 以及两个半监督的生成模型,即 VAE 和 AC-GAN。邪门模型之所以邪门,主要在于它能给我一种初看觉得 “卧槽这也能编码图像数据做分类” 而细看又觉得 “怎么这么合理啊” 的感觉。
而本文正是基于笔者对模型架构的认知,针对复现时遇到的许多现象提出自己的理解。因此必然会有值得商榷之处。也欢迎大家在评论区讨论。
复现使用的代码框架
除了后面的生成式模型,本文的一系列复现基于下面的代码,代码运行在 Kaggle 的 Jupyter Notebook 上面。所以我根据 Notebook 的每一个 Cell 来给出代码。
这个代码框架的大致介绍是:通过模型暴露的一个接口函数 get_model_on_device() 获取模型实例,然后使用 hyperopt 框架,在 CIFAR-10 数据集上分割 20% 数据用以对模型进行全局学习率和训练轮次的早停法调参;获取最优参数后,在全量数据上进行训练,最后收集训练信息得到结果和部分数据变化的可视化图像。
由于每一次都要花大量时间寻找合适的学习率,笔者花了一天时间研究了一下 muP(Paper link here) 的原理以及怎样迁移学习率,结论:在已有数据上(MLP, CNN, ResNet-18)进行的实验和相关理论计算证明,模型架构(残差连接,BN 等)会影响损失地形(Paper link here),导致跨架构的学习率迁移失效。其实很明显,比如微调 ResNet 就比从零训练 ResNet 的 best LR更低,因为预训练权重已经在一个最小值附近了,损失地形比起随机点位更平坦。所以该花时间调参还得花时间调参。不过,可以考虑在小宽度模型上再 scale up,这样就符合 muP 的初心了。具体的实验过程,还请大家参阅后文。不过笔者在这上面探索不多,毕竟主要做的是跨架构的复现工作。后面的训练确实得花比较多的时间粗调学习率。
当然,这个框架也有缺陷,主要是它只能对端到端的网络进行一键式训练和评估,像 VAE 和 AC-GAN 这种标签辅助的生成网络,就需要自行修改了。
下面是每一个 Cell 的代码:
Cell 1: 引入必要的库以及设置设备
| import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, random_split, Subset
import matplotlib.pyplot as plt
import numpy as np
import time
# 导入 hyperopt 用于超参数调优
from hyperopt import fmin, tpe, hp, Trials, STATUS_OK
# 导入 tqdm,在 jupyter 中使用 notebook 版本
from tqdm.notebook import tqdm
# torch.manual_seed(3407) is all you need!
# 为了实验复现性使用的手动种子。
torch.manual_seed(3407)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"using device: {device}")
|
Cell 2: 调优和训练使用的参数
| # --- Hyperopt 调优参数 ---
TUNE_DATA_PERCENT = 0.2 # 使用 20% 的数据进行快速调优
TUNE_MAX_EPOCHS = 50 # 调优时,每个试验最多训练的 epoch 数
PATIENCE = 5 # 早停法:验证损失连续 5 个 epoch 没有改善就停止
MAX_EVALS = 20 # 调优总共尝试的次数
LR_SEARCH_RANGE = (-10, -4) # 学习率对数搜索范围,也就是 exp(-4)~exp(-10) 大概 2e-2 到4e-5 之间
# --- 最终训练参数,这里只是声明,具体值由调优过程决定 ---
BEST_LEARNING_RATE = None
BEST_EPOCHS = None
BATCH_SIZE = 128
|
Cell 3: 绘图和评估相关函数
| def evaluate_model(model, data_loader, criterion, device):
"""评估模型,返回平均损失和准确率"""
model.eval()
total_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in data_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
total_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_loss = total_loss / total
accuracy = 100 * correct / total
return avg_loss, accuracy
def count_parameters(model):
"""计算模型的可训练参数数量"""
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def plot_and_save_history(history, filename="training_curves.png"):
"""绘制并保存训练过程中的损失和准确率曲线"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(18, 6))
# 绘制损失曲线 (训练 vs 验证/测试)
ax1.plot(history['train_loss'], label='Training Loss', color='blue')
if 'val_loss' in history:
ax1.plot(history['val_loss'], label='Validation Loss', color='green')
ax1.set_title('Loss over Epochs', fontsize=16)
ax1.set_xlabel('Epoch', fontsize=12)
ax1.set_ylabel('Loss', fontsize=12)
ax1.grid(True)
ax1.legend()
# 绘制准确率曲线
if 'val_accuracy' in history:
ax2.plot(history['val_accuracy'], label='Validation Accuracy', color='orange')
ax2.set_title('Accuracy over Epochs', fontsize=16)
ax2.set_xlabel('Epoch', fontsize=12)
ax2.set_ylabel('Accuracy (%)', fontsize=12)
ax2.grid(True)
ax2.legend()
plt.tight_layout()
plt.savefig(filename, bbox_inches='tight')
print(f"Traing curve saved at {filename}")
plt.show()
|
Cell 4: 定义模型
| """
这里使用 MLP 作为示例。为了保证框架和模型解耦,统一只暴露一个 get_model_on_device 的无参数函数用以返回新的模型实例。
"""
# 模型结构参数
INPUT_SIZE = 32 * 32 * 3
HIDDEN_SIZE_1 = 512
HIDDEN_SIZE_2 = 256
class MLP(nn.Module):
def __init__(self, input_size, hidden_size_1, hidden_size_2, num_classes):
super(MLP, self).__init__()
self.network = nn.Sequential(
nn.Flatten(), # 将 3x32x32 的图像展平成一维向量
nn.Linear(input_size, hidden_size_1),
nn.ReLU(),
nn.Linear(hidden_size_1, hidden_size_2),
nn.ReLU(),
nn.Linear(hidden_size_2, num_classes)
)
def forward(self, x):
return self.network(x)
# 对外接口,方便后续实验改模型结构
def get_model_on_device():
return MLP(INPUT_SIZE, HIDDEN_SIZE_1, HIDDEN_SIZE_2, NUM_CLASSES).to(device)
|
Cell 5: 加载并划分数据集
| # 数据集参数
NUM_CLASSES = 10
# 定义数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
(0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)
)
])
# 加载完整的 CIFAR-10 训练集
full_train_dataset = torchvision.datasets.CIFAR10(
root='./data',
train=True,
transform=transform,
download=True
)
# --- 为调优创建小规模数据集 ---
num_total_train = len(full_train_dataset)
tune_subset_size = int(num_total_train * TUNE_DATA_PERCENT)
# 随机抽取 20% 的数据索引
indices = torch.randperm(num_total_train).tolist()
tune_indices = indices[:tune_subset_size]
# 创建一个只包含这 20% 数据的数据集子集
tune_dataset = Subset(full_train_dataset, tune_indices)
# 将这个子集再划分为训练集和验证集 (80% train, 20% val)
num_tune = len(tune_dataset)
val_size_tune = int(num_tune * 0.2)
train_size_tune = num_tune - val_size_tune
train_subset_tune, val_subset_tune = random_split(tune_dataset, [train_size_tune, val_size_tune])
# 创建用于调优的数据加载器
train_loader_tune = DataLoader(dataset=train_subset_tune, batch_size=BATCH_SIZE, shuffle=True)
val_loader_tune = DataLoader(dataset=val_subset_tune, batch_size=BATCH_SIZE, shuffle=False)
print(f"total samples being used for hyperopt: {len(tune_dataset)}")
print(f"Train set size: {len(train_subset_tune)}")
print(f"Validation set size: {len(val_subset_tune)}")
|
Cell 6: 使用 hyperopt 对模型进行超参数搜索
| def objective(params):
"""Hyperopt 优化的目标函数"""
lr = params['lr']
model = get_model_on_device()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
best_val_loss = float('inf')
epochs_no_improve = 0
best_epoch = 0
# 使用 tqdm 可视化每个 trial 的 epoch 进度
epoch_iterator = tqdm(range(TUNE_MAX_EPOCHS), desc=f"LR {lr:.6f}", leave=False)
for epoch in epoch_iterator:
model.train()
for images, labels in train_loader_tune:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
val_loss, val_accuracy = evaluate_model(model, val_loader_tune, criterion, device)
# 更新进度条显示当前验证损失
epoch_iterator.set_postfix({'val_loss': f'{val_loss:.4f}'})
if val_loss < best_val_loss:
best_val_loss = val_loss
epochs_no_improve = 0
best_epoch = epoch + 1
else:
epochs_no_improve += 1
if epochs_no_improve == PATIENCE:
print(f"Early stopping triggered at epoch {epoch + 1}")
break
return {'loss': best_val_loss, 'status': STATUS_OK, 'best_epoch': best_epoch}
# 定义学习率的搜索空间
space = {'lr': hp.loguniform('lr', *LR_SEARCH_RANGE)}
print("--- Start finding best hyper parameters ---")
trials = Trials()
best_params = fmin(
fn=objective,
space=space,
algo=tpe.suggest,
max_evals=MAX_EVALS,
trials=trials,
)
# 从 trials 对象中找到最佳试验的结果
best_trial = trials.best_trial
BEST_LEARNING_RATE = best_params['lr']
BEST_EPOCHS = best_trial['result']['best_epoch']
print("\n--- Best hyper parameters found ---")
print(f"Best LR: {BEST_LEARNING_RATE:.6f}")
print(f"Best epochs: {BEST_EPOCHS}")
|
Cell 7: 在完整训练集上进行训练并监控性能
| print("\n--- Start training on full training set ---")
# 使用完整的训练数据集 (50000张图片)
full_train_loader = DataLoader(dataset=full_train_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 测试集加载器
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=transform)
test_loader = DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 重新实例化模型和优化器
final_model = get_model_on_device()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(final_model.parameters(), lr=BEST_LEARNING_RATE)
history = {'train_loss': [], 'val_loss': [], 'val_accuracy': []}
start_time = time.time()
for epoch in range(BEST_EPOCHS):
# --- 训练 ---
final_model.train()
running_loss = 0.0
train_iterator = tqdm(full_train_loader, desc=f"Epoch {epoch+1}/{BEST_EPOCHS}", leave=False)
for images, labels in train_iterator:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = final_model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * images.size(0)
epoch_train_loss = running_loss / len(full_train_loader.dataset)
history['train_loss'].append(epoch_train_loss)
# --- 在测试集上评估以监控性能 ---
epoch_val_loss, epoch_val_accuracy = evaluate_model(final_model, test_loader, criterion, device)
history['val_loss'].append(epoch_val_loss)
history['val_accuracy'].append(epoch_val_accuracy)
print(f"Epoch [{epoch+1}/{BEST_EPOCHS}], Train Loss: {epoch_train_loss:.4f}, Test Loss: {epoch_val_loss:.4f}, Test Accuracy: {epoch_val_accuracy:.2f}%")
end_time = time.time()
training_duration = end_time - start_time
print("--- Over ---")
|
Cell 8: 生成实验的结果报告
| # 计算最终模型在测试集上的性能
final_test_loss, final_test_accuracy = evaluate_model(final_model, test_loader, criterion, device)
# 计算模型参数量
total_params = count_parameters(final_model)
# 格式化训练时长
mins, secs = divmod(training_duration, 60)
formatted_duration = f"{int(mins)}m {int(secs)}s"
# 绘制并保存性能曲线
report_history = {
'train_loss': history['train_loss'],
'val_loss': history['val_loss'],
'val_accuracy': history['val_accuracy']
}
plot_and_save_history(report_history)
# 打印报告
print("\n" + "="*50)
print(" " * 15 + "Results")
print("="*50)
print("\n[Hyper parameters]")
print(f" - Best LR: {BEST_LEARNING_RATE:.6f}")
print(f" - Best epochs: {BEST_EPOCHS} epochs")
print(f" - Batch size: {BATCH_SIZE}")
print("\n[Model structure]")
print(f" - Model type: MLP")
print(f" - Model structure:")
print(final_model)
print(f" - Total params: {total_params:,}")
print("\n[Training infomation]")
print(f" - Training duration on full training set: {formatted_duration}")
platform = "Kaggle's free P100, Thank you Google!" if torch.cuda.is_available() else "some poor guy's broken Intel core"
print(f" - Training device: {device} on {platform}")
print("\n[Benchmarks on test set]")
print(f" - Test loss: {final_test_loss:.4f}")
print(f" - Test accuracy: {final_test_accuracy:.2f}%")
print("\n" + "="*50)
|
MLP
MLP 模型的训练结果展示
MLP 的训练结果
| ==================================================
Results
==================================================
[Hyper parameters]
- Best LR: 0.000056
- Best epochs: 13 epochs
- Batch size: 128
[Model structure]
- Model type: MLP
- Model structure:
MLP(
(network): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=3072, out_features=512, bias=True)
(2): ReLU()
(3): Linear(in_features=512, out_features=256, bias=True)
(4): ReLU()
(5): Linear(in_features=256, out_features=10, bias=True)
)
)
- Total params: 1,707,274
[Training infomation]
- Training duration on full training set: 2m 51s
- Training device: cuda on Kaggle's free P100, Thank you Google!
[Benchmarks on test set]
- Test loss: 1.3208
- Test accuracy: 54.44%
==================================================
|
训练代码已经放在前面了,这里就不给出了。
对 MLP 模型的解读和评述
模型结构图:
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Graph direction and styling
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef result fill:#45475a,stroke:#a6e3a1,stroke-width:2px,color:#cdd6f4;
%% Input Layer
subgraph Input["Input Layer"]
A[("RGB Image<br>3x32x32")]
end
class Input input;
%% Flatten Layer
subgraph Flatten["Flatten Layer"]
B[("Flatten")]
end
A --> |3 @ 32x32| B
class Flatten box;
%% Hidden Layer 1
subgraph Hidden1["Hidden Layer 1"]
C["Linear<br>3072x512"]
D["ReLU"]
end
B -->|3072| C --> D
class Hidden1 box;
%% Hidden Layer 2
subgraph Hidden2["Hidden Layer 2"]
E["Linear<br>512x256"]
F["ReLU"]
end
D -->|512| E --> F
class Hidden2 box;
%% Output Layer
subgraph Output["Output Layer"]
G["Linear<br>256x10"]
end
F -->|256| G
class Output output;
%% Classification Result
subgraph Result["Classification Result"]
H[("10 output logits")]
end
G -->|10| H
class Result result;
%% Styling
style A stroke-dasharray: 5 5
style H stroke:#a6e3a1,stroke-width:3px
MLP 是利用 \(\mathbb{R}^n\rightarrow\mathbb{R}^m\) 的多重线性映射实现数据的降维,但是单纯的线性映射嵌套仍是 \(\mathbb{R}^{d_{in}}\rightarrow\mathbb{R}^{d_{out}}\) 的线性映射,因此需要在层与层之间添加非线性的激活函数引入非线性。这样一个足够宽的两层全连接网络即可拟合任意函数。
在这个任务里面,我们使用一个三层的 MLP,并采用 ReLU 作为层间的激活函数,由于我们对 one-hot 向量进行分类,因此使用交叉熵损失,如果用 MSE 的话,求导之后会发现它是交叉熵的导数乘以权重,这就不适合梯度稳定更新。
输入上是将 3@32x32 的图像展平成 3072 维的向量。当然我觉得这很没道理,图像本身就有两个维度三个通道,这种“平面化”的信息,感觉就被一个 nn.Flatten 给丢弃了。虽然说理论上经过足够数据训练之后,一个 fc layer 足够有能力提取各个维度上的相关性(万能拟合定理),但是网络要足够宽,数据要足够多,正则化要足够充分,而如果不引入更多先验知识来捕捉图像信息的特征,训练效率和参数效率都是极其低下的。
这是一个三层的多层感知机,参数量 1.7M。第一次训练下来发现这点参数量反映下来就是即使是 P100 这种老 GPU 都根本没使劲,倒是 CPU 一直在满负荷发力,搬运数据。后来意识到,dataloader 里面可以写上 num_workers=6 以及 pin_memory=True 来提升访存效率,并且把 batch_size 调大(反正就 2 M不到的模型爆不了显存),训练效率高了很多啊。
经过 13 个 Epoch 的训练之后,模型在 CIFAR-10 上只取得了 54.44% 的准确率。增大模型的宽度和深度理论上可以改善,但是效率太低了(关于宽度和深度的思考,可以参考 EfficientNet 的论文)。因此需要发掘图像信息的特性,在模型结构上面引入更多先验信息,寻找能够更高效提取信息的架构。所以可以看到现在的网络架构中,MLP 仅仅是作为分类头出现的。
CNN
CNN 模型的训练结果展示
CNN 的代码实现
| class CNN(nn.Module):
def __init__(self,
input_channels=3,
num_classes=10,
channels=[32, 64, 128], # 每个卷积块的输出通道数
kernel_sizes=[3, 3, 3], # 每个卷积层的 kernel 大小
dropout_rate=0.5, # dropout 概率
use_batchnorm=True): # 是否使用批归一化
super(CNN, self).__init__()
# 存储配置参数
self.config = {
'input_channels': input_channels,
'num_classes': num_classes,
'channels': channels,
'kernel_sizes': kernel_sizes,
'dropout_rate': dropout_rate,
'use_batchnorm': use_batchnorm
}
# 确保卷积层数量与 kernel 大小数量一致
assert len(channels) == len(kernel_sizes), \
"通道数列表与kernel大小列表长度必须一致"
# 构建卷积层
self.features = nn.Sequential()
in_channels = input_channels
for i, (out_channels, kernel_size) in enumerate(zip(channels, kernel_sizes)):
# 卷积层
self.features.add_module(
f'conv{i+1}',
nn.Conv2d(in_channels, out_channels, kernel_size, padding=kernel_size//2)
)
# 批归一化层(可选)
if use_batchnorm:
self.features.add_module(
f'bn{i+1}',
nn.BatchNorm2d(out_channels)
)
# 激活函数
self.features.add_module(f'relu{i+1}', nn.ReLU(inplace=True))
# 池化层
self.features.add_module(f'pool{i+1}', nn.MaxPool2d(2, 2))
in_channels = out_channels
# 计算卷积层输出后的特征图尺寸
# CIFAR-10输入为32x32,经过n次池化后尺寸为32/(2^n)
self.feature_size = in_channels * (32 // (2 ** len(channels))) ** 2
# 构建全连接层
self.classifier = nn.Sequential(
nn.Linear(self.feature_size, 512),
nn.ReLU(inplace=True),
nn.Dropout(dropout_rate),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1) # 展平特征图
x = self.classifier(x)
return x
def get_model_on_device():
return CNN().to(device)
|
CNN 的训练结果
| ==================================================
Results
==================================================
[Hyper parameters]
- Best LR: 0.000199
- Best epochs: 16 epochs
- Batch size: 128
[Model structure]
- Model type: CNN
- Model structure:
CNN(
(features): Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu3): ReLU(inplace=True)
(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=2048, out_features=512, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=512, out_features=10, bias=True)
)
)
- Total params: 1,147,914
[Training infomation]
- Training duration on full training set: 4m 7s
- Training device: cuda on Kaggle's free P100, Thank you Google!
[Benchmarks on test set]
- Test loss: 0.7026
- Test accuracy: 77.33%
==================================================
|
对 CNN 模型的解读和评述
结构图(请放大观看):
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef result fill:#45475a,stroke:#a6e3a1,stroke-width:2px,color:#cdd6f4;
classDef conv fill:#313244,stroke:#74c7ec,stroke-width:2px,color:#cdd6f4;
%% Input Layer
subgraph Input["Input"]
A[("3@32×32")]
end
class Input input;
%% Feature Extractor
%% -- Conv Block 1 --
subgraph Block1["Conv Block 1"]
B["Conv2d<br> 3x32 x 3×3 kernel"]
C["BatchNorm2d<br> 32 channels"]
D["ReLU"]
E["MaxPool2d<br> 2×2/2"]
end
A --> B
B -->|32 @ 32x32| C --> D --> E
class Block1 conv;
%% -- Conv Block 2 --
subgraph Block2["Conv Block 2"]
F["Conv2d<br> 32x64 x 3×3 kernel"]
G["BatchNorm2d<br> 64 channels"]
H["ReLU"]
I["MaxPool2d<br> 2×2/2"]
end
E --> |32 @ 16×16| F
F --> |64 @ 16×16| G --> H --> I
class Block2 conv;
%% -- Conv Block 3 --
subgraph Block3["Conv Block 3"]
J["Conv2d<br> 64x128 x 3×3 kernel"]
K["BatchNorm2d<br> 128 channels"]
L["ReLU"]
M["MaxPool2d<br> 2×2/2"]
end
I --> |64 @ 8×8| J
J --> |128 @ 8×8| K --> L --> M
class Block3 conv;
%% Feature Flattening
subgraph Flatten["Flatten"]
N[("2048")]
end
M --> |128 @ 4×4| N
class Flatten box;
%% Classifier
subgraph Classifier["Classifier"]
O["Linear<br> 2048x512"]
P["ReLU"]
Q["Dropout<br> p = 0.5"]
R["Linear<br> 512x10"]
end
N --> O
O --> P --> Q --> R
class Classifier box;
%% Output Layer
subgraph Output["Classification Result"]
S[("10 output logits")]
end
R --> S
class Output output;
%% Styling
style A stroke-dasharray: 5 5
style S stroke:#a6e3a1,stroke-width:3px
conv2d 就是卷积操作,本质上是从输入张量 (batch_size, in_channel, H, W) 到输出张量 (batch_size, out_channel, H, W) 的一个利用四维张量 (in_channel, out_channel, H', W') 的卷积核进行的卷积操作,具体是对于单张图像的各个通道进行填充后,将自定义的 in_channel@H'xW' 的矩阵在其上一一对应进行滑动覆盖,并对覆盖到的区域进行逐元素求积并求和,得到了单个新矩阵,如此共选取 out_channel 次自定义矩阵,就得到了输出张量 (batch_size, out_channel, H, W) 这是任意一本深度学习教材都会讲解的内容。
CNN 通过先验引入稀疏连接(也就是 conv2d )不仅可以实现对更大规模网络的稀疏近似,满足图像的平移不变性,还具有很好的可解释性(卷积核对应一个小面积的感受野,解决之前提到 MLP 的展平操作的问题,并且不同的卷积核提取不同的特征)。因此相当适合图像处理。当然最后还是得依靠一个 MLP 作为分类头,不过这里的展平操作就合理多了,因为经过多次 conv2d 之后,模型提取到的都是空间上弱相关的深层次(抽象)特征了。在这些特征之间进行组合就非常合理且直观了。在很长的一段时间内,CNN 作为高效的特征提取器,一直都是各种 CV 网络的砖石。
这个网络虽然参数量不如先前的 MLP,但是宽度要宽一些(我理解的网络宽度即通道数,因为这决定了模型捕获的特征数量),根据 muP 的理论,学习率可以翻 4 倍(MLP隐藏层维度 512, CNN 最大通道数 128),结论大致符合预期。CNN 的高效性正在于其中,以更低的参数量获得更优的效果。
后面的 NiN, VGG, GoogLeNet 等都是基于卷积摆放位置和多少以及并行度的差异,详细的复现敬请期待。
ResNet
ResNet-18 模型的训练结果展示
代码
| from torchvision.models import resnet18
class ResNet18(nn.Module):
def __init__(self, pretrained=False, num_classes=10):
super(ResNet18, self).__init__()
# 加载预训练或随机初始化的ResNet-18
self.resnet = resnet18(pretrained=pretrained)
# 调整第一个卷积层以适应32x32输入
# 原始ResNet-18的第一个卷积层是7x7, stride=2, padding=3
# 对于32x32图像,我们改为3x3, stride=1, padding=1
self.resnet.conv1 = nn.Conv2d(
3, 64, kernel_size=3, stride=1, padding=1, bias=False
)
# 调整最大池化层,不需要下采样太多
self.resnet.maxpool = nn.Identity() # 移除最大池化层
# 调整最后一个全连接层以适应CIFAR-10的10个类别
in_features = self.resnet.fc.in_features
self.resnet.fc = nn.Linear(in_features, num_classes)
def forward(self, x):
return self.resnet(x)
def get_model_on_device():
model = ResNet18()# pretrained=True 使用预训练权重,反之不使用。
return model.to(device)
|
从零训练结果
| ==================================================
Results
==================================================
[Hyper parameters]
- Best LR: 0.002787
- Best epochs: 8 epochs
- Batch size: 128
[Model structure]
- Model type: ResNet18 from scrach
- Model structure:
ResNet18(
(resnet): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): Identity()
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)
)
- Total params: 11,173,962
[Training infomation]
- Training duration on full training set: 5m 8s
- Training device: cuda on Kaggle's free P100, Thank you Google!
[Benchmarks on test set]
- Test loss: 0.5767
- Test accuracy: 83.46%
==================================================
|
微调结果
| ==================================================
Results
==================================================
[Hyper parameters]
- Best LR: 0.000330
- Best epochs: 3 epochs
- Batch size: 128
[Model structure]
- Model type: Pretrained ResNet18
- Model structure:
ResNet18(
(resnet): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): Identity()
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)
)
- Total params: 11,173,962
[Training infomation]
- Training duration on full training set: 1m 55s
- Training device: cuda on Kaggle's free P100, Thank you Google!
[Benchmarks on test set]
- Test loss: 0.3450
- Test accuracy: 89.06%
==================================================
|
对 ResNet-18 模型的解读和评述
考虑到笔者使用的 GPU 性能较弱,本次使用的是 ResNet-18 架构,这是一个相对浅的 ResNet,相比于 ResNet-50 等基于 BottleNeck 块的网络,ResNet-18 由稍有不同的 BasicBlock 组成。
ResNet-18 的结构如下所示:
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef result fill:#45475a,stroke:#a6e3a1,stroke-width:2px,color:#cdd6f4;
classDef conv fill:#313244,stroke:#74c7ec,stroke-width:2px,color:#cdd6f4;
%% Input Layer
subgraph Input["Input"]
A[("3 @ 32×32")]
end
class Input input;
%% Initial Convolution
subgraph InitConv["Initial Convolution"]
B["Conv2d <br> 3x64 x 3×3"]
C["BatchNorm2d <br> 64 channels"]
D["ReLU"]
end
A --> B
B --> C --> D
class InitConv conv;
%% Layer 1 (2× BasicBlock without downsample)
subgraph Layer1["Layer1 (2×BasicBlock)"]
F["BasicBlock 1"]
G["BasicBlock 1"]
end
D --> |64 @ 32×32| F
F --> |64 @ 32×32| G
class Layer1 box;
%% Layer 2 (2× BasicBlock with downsample in first block)
subgraph Layer2["Layer2 (2×BasicBlock)"]
H["BasicBlock 2"]
I["BasicBlock 1"]
end
G --> |64 @ 32×32| H
H --> |128 @ 16×16| I
class Layer2 box;
%% Layer 3 (2× BasicBlock with downsample in first block)
subgraph Layer3["Layer3 (2×BasicBlock)"]
J["BasicBlock 2"]
K["BasicBlock 1"]
end
I --> |128 @ 16×16| J
J --> |256 @ 8×8| K
class Layer3 box;
%% Layer 4 (2× BasicBlock with downsample in first block)
subgraph Layer4["Layer4 (2×BasicBlock)"]
L["BasicBlock 2"]
M["BasicBlock 1"]
end
K --> |256 @ 8×8| L
L --> |512 @ 4×4| M
class Layer4 box;
%% Global Pooling and FC
subgraph PoolFC["GAP & Classfiaction"]
N["AdaptiveAvgPool2d <br> 1×1"]
O["Flatten <br> 512-dim vec"]
P["Linear <br> 512x10"]
end
M --> |512 @ 4×4| N --> |512 @ 1×1| O --> |512| P
class PoolFC box;
%% Output Layer
subgraph Output["output"]
Q[("10")]
end
P --> Q
class Output output;
%% Styling
style A stroke-dasharray: 5 5
style Q stroke:#a6e3a1,stroke-width:3px
其中,Basic block 1 是不带降采样的残差连接:
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef residual fill:#313244,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
%% BasicBlock Structure (No Downsample)
subgraph BasicBlockNoDS["BasicBlock 1"]
A["Conv2d <br> 64x64 x 3×3"]
B["BatchNorm2d <br> 64 channels"]
C["ReLU"]
D["Conv2d <br> 64x64 x 3×3"]
E["BatchNorm2d <br> 64 channels"]
F(("+"))
G["ReLU"]
end
%% Input
Input[("64 @ H×W")] --> A
Input --> F
%% Connections
A --> B --> C --> D --> E --> F
F --> G
%% Output
G --> Output[("64 @ H×W")]
class BasicBlockNoDS residual;
Basic block 2 是带降采样的残差连接:
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef residual fill:#313244,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
classDef downsample fill:#313244,stroke:#74c7ec,stroke-width:2px,color:#cdd6f4;
%% BasicBlock Structure (With Downsample)
subgraph BasicBlockWithDS["BasicBlock 2"]
A["Conv2d <br> 64x128 x 3×3 /2"]
B["BatchNorm2d <br> 128 channels"]
C["ReLU"]
D["Conv2d: 128x128 x 3×3"]
E["BatchNorm2d <br> 128 channels"]
F(("+"))
G["ReLU"]
subgraph Downsample["Downsampling"]
H["Conv2d: 64x128 x 1×1 /2"]
I["BatchNorm2d <br> 128 channels"]
end
end
%% Input
Input[("64 @ H×W")] --> A
Input --> H
%% Connections
A --> B --> C --> D --> E --> F
H --> I --> F
F --> G
%% Output
G --> Output[("128 @ H/2×W/2")]
class BasicBlockWithDS residual;
class Downsample downsample;
ResNet-18 的结构(在长宽维度)正如一个漏斗一样,除了初始化层和 Layer 1 以外,其余的 Layer 都是 Basic block 2 -> Basic block 1 的结构,也就是归纳特征到提取特征的一个顺序。最后使用自适应性池化来应对不同的输入。因为 torch 提供的 ResNet-18 是基于 ImageNet 设计的,输入是 3@224x224,利用自适应性池化,就可以只用修改对输入的处理了。
除此之外,ResNet 使用了多种技术才使如此深层的网络成为可能。
一是使用 ReLU 激活。其他激活函数如 sigmoid,其导数在 \([-1,1]\) 之间,这就导致梯度向深层流动的时候不断被一个绝对值小于 \(1\) 的数乘起来,逐渐消失。ReLU 求导要么 \(0\) 要么 \(1\),也就是梯度要么在负数输出处停止流动要么就直接原封不动传下去。
二是使用 BatchNorm2d。批归一化试图将数据拉回标准正态分布,这解耦了层与层之间的输入依赖,相当于每一层都只用将一批标准正态数据映射到标准正态数据,独立性大大增强,反映到损失地形上,就是对模型的微扰(也就是优化器带来的参数更新)带来的(可能的)巨大扰动(即崎岖的损失地形)给平坦化了。
当然上面的两点在一般的 CNN 中都有使用,像 GoogLeNet 这种基于 Inception 的网络也只有 22 层,但是基于 ResNet 的网络可以轻松达到成百上千层,关键在于——
三是残差连接。Kaiming 意识到以下对比:考虑一般的神经网络单层
\[
y=\phi (\mathrm{Layer}(x))
\]
其中 \(y\) 为输出,\(\phi\) 为激活函数,\(\mathrm{Layer}\) 为对输入 \(x\) 做的操作,比如矩阵乘法或者卷积等。
那么向前传递的梯度为
\[
\dfrac{\partial y}{\partial x}=\dfrac{\partial \mathrm{Layer}}{\partial x}\phi' (\mathrm{Layer}(x))
\]
也就是一个数乘以小于等于 \(1\) 的数。但是,如果我们考虑这样的单层:
\[
y=\phi (x+\mathrm{Layer}(x))
\]
那么向前传递的梯度为
\[
\dfrac{\partial y}{\partial x}=(1+\dfrac{\partial \mathrm{Layer}}{\partial x})\phi' (\mathrm{Layer}(x))
\]
嗯,这样传递到的梯度确实变多了,但是还是受制于激活函数的导数啊,感觉……用处不大?
呵呵,事情没有那么简单。要不回头看看网络结构里面ReLU的位置到底在哪里呢?
是在两个 conv2d 的中间!也就是说,事实上顺序应该是
\[
y=x+\phi (\mathrm{Layer}(x))
\]
那么向前传递的梯度为
\[
\dfrac{\partial y}{\partial x}=1+\dfrac{\partial \mathrm{Layer}}{\partial x}\phi' (\mathrm{Layer}(x))
\]
这样,不管自己梯度多少,深层的梯度就都能顺畅流动到浅层了。
当然 Kaiming 在论文里面的观点是恒等变换不易学习所以转而学习残差,这样即使什么都没有学到,至少还能保留恒等映射的能力。不过我更喜欢从数学角度推导咯~
最后可以看到 ResNet-18 虽然宽度比 CNN 大一倍,但是居然可以承受比 CNN 大好几个数量级的学习率,原因就在于这几个方案使得损失地形极度平滑,参数更新量即使比较大,也不会有特别大的震荡。然后 muP 的理论在这里就完全失效了,毕竟 muP 研究的是同一模型不同尺度的参数调整规律。
后面我使用 torch 官方提供的在 ImageNet 上预训练的权重,使用更小的学习率就可以得到更加的效果,果然预训练就是最佳的参数初始化策略啊。
可以看到 ResNet 的测试准确率有上了一个台阶。网上也是到处都有 ResNet 爆改 YOLOv8 骨干网络的博客,看来大家都很喜欢残差连接啊。
ResNet-50, ResNeXt, DenseNet, EfficientNet 等架构中也是将残差连接作为基础(DenseNet 更是扩展了这一思路)。这些网络的复现和讲解敬请期待。
下面的 Transformer 模型也利用了残差连接。甚至 FCN 和 U-Net 等也汲取了类似的思路引入了跳跃连接。这一部分的复现请参考本系列博客的 第二篇。
毕竟参数量够大,Scaling law 持续发力中......不过提到 Scaling law,怎么能不请出我们的 Transformer 模型呢?
ViT
ViT 模型的训练结果展示
nanoViT 的训练代码
| from torch import Tensor
class PatchEmbedding(nn.Module):
"""将图像分割为补丁并进行嵌入"""
def __init__(self, img_size=32, patch_size=2, in_channels=3, embed_dim=128):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
# 计算补丁数量
self.num_patches = (img_size // patch_size) ** 2
# 使用卷积层实现补丁嵌入 (等价于每个补丁应用一个卷积核)
self.proj = nn.Conv2d(
in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x: Tensor) -> Tensor:
# x形状: (batch_size, in_channels, img_size, img_size)
x = self.proj(x) # 输出形状: (batch_size, embed_dim, num_patches^(1/2), num_patches^(1/2))
x = x.flatten(2) # 输出形状: (batch_size, embed_dim, num_patches)
x = x.transpose(1, 2) # 输出形状: (batch_size, num_patches, embed_dim)
return x
class TransformerClassifier(nn.Module):
"""用于CIFAR-10分类的Transformer模型"""
def __init__(
self,
img_size=32,
patch_size=2,
in_channels=3,
num_classes=10,
embed_dim=128,
depth=4, # Transformer编码器层数
num_heads=4, # 注意力头数
mlp_ratio=2.0, # MLP隐藏层维度比例
dropout=0.1, # Dropout概率
):
super().__init__()
# 补丁嵌入
self.patch_embed = PatchEmbedding(
img_size=img_size,
patch_size=patch_size,
in_channels=in_channels,
embed_dim=embed_dim
)
num_patches = self.patch_embed.num_patches
# 类别令牌 (用于最终分类)
self.class_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
# 位置嵌入 (可学习)
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
# Dropout层
self.pos_drop = nn.Dropout(p=dropout)
# Transformer编码器
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim,
nhead=num_heads,
dim_feedforward=int(embed_dim * mlp_ratio),
dropout=dropout,
batch_first=True, # 批处理维度在前
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=depth)
# 分类头
self.classifier = nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(embed_dim, num_classes)
)
def forward(self, x: Tensor) -> Tensor:
# x形状: (batch_size, 3, 32, 32)
batch_size = x.shape[0]
# 补丁嵌入
x = self.patch_embed(x) # 输出形状: (batch_size, num_patches, embed_dim)
# 扩展类别令牌到批次大小
class_tokens = self.class_token.expand(batch_size, -1, -1) # 形状: (batch_size, 1, embed_dim)
# 将类别令牌与补丁嵌入拼接
x = torch.cat((class_tokens, x), dim=1) # 形状: (batch_size, num_patches + 1, embed_dim)
# 添加位置嵌入并应用dropout
x = x + self.pos_embed
x = self.pos_drop(x)
# Transformer编码
x = self.transformer_encoder(x) # 形状: (batch_size, num_patches + 1, embed_dim)
# 使用类别令牌的输出进行分类
x = x[:, 0] # 取类别令牌对应的输出,形状: (batch_size, embed_dim)
x = self.classifier(x) # 形状: (batch_size, num_classes)
return x
def get_model_on_device():
model = TransformerClassifier(
img_size=32,
patch_size=2,
in_channels=3,
num_classes=10,
embed_dim=192,
depth=4,
num_heads=8,
mlp_ratio=2.0,
dropout=0.1
)
return model.to(device)
|
ViT-B-16 的微调代码(原理)
| import torch
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as T
from torchvision.models import ViT_B_16_Weights
class ViT_Cifar10(nn.Module):
"""
一个真正“即插即用”的ViT-B/16模型,专门用于CIFAR-10。
这个类会自动处理输入尺寸不匹配的问题:
1. 内置一个上采样层,在前向传播时自动将输入的32x32图像放大到224x224。
2. 加载在ImageNet上预训练的ViT-B/16权重。
3. 将分类头替换为适用于CIFAR-10的10个类别。
"""
def __init__(self, num_classes: int = 10):
super().__init__()
# 步骤1: 定义一个上采样/调整大小的层
# T.Resize 是 torchvision.transforms 中的一个类,它可以作为 nn.Module 使用
self.upsampler = T.Resize((224, 224), antialias=True)
# 步骤2: 加载预训练的ViT模型
self.vit = models.vit_b_16(weights=ViT_B_16_Weights.IMAGENET1K_V1)
# 步骤3: 冻结主干网络的所有参数
for param in self.vit.parameters():
param.requires_grad = False
# 步骤4: 替换分类头
in_features = self.vit.heads.head.in_features
self.vit.heads.head = nn.Linear(in_features=in_features, out_features=num_classes)
# 确保新分类头的参数是可训练的
for param in self.vit.heads.parameters():
param.requires_grad = True
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
定义模型的前向传播。
Args:
x (torch.Tensor): 输入的图像张量,可以是 (B, 3, 32, 32)
Returns:
torch.Tensor: 模型输出的logits,形状为 (B, num_classes)
"""
# --- 关键改动 ---
# 在送入ViT之前,首先将输入图像上采样到224x224
x = self.upsampler(x)
# 现在,尺寸匹配了,可以安全地调用ViT
return self.vit(x)
def get_model_on_device():
"""
实例化ViTForCifar10模型,并将其移动到在主作用域中定义的设备上。
Returns:
ViTForCifar10: 配置好并移动到设备上的模型实例。
"""
model = ViT_Cifar10(num_classes=10)
return model.to(device)
|
nanoViT 的训练结果
| ==================================================
Results
==================================================
[Hyper parameters]
- Best LR: 0.000232
- Best epochs: 16 epochs
- Batch size: 128
[Model structure]
- Model type: ViT
- Model structure:
TransformerClassifier(
(patch_embed): PatchEmbedding(
(proj): Conv2d(3, 192, kernel_size=(2, 2), stride=(2, 2))
)
(pos_drop): Dropout(p=0.1, inplace=False)
(transformer_encoder): TransformerEncoder(
(layers): ModuleList(
(0-3): 4 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=192, out_features=192, bias=True)
)
(linear1): Linear(in_features=192, out_features=384, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=384, out_features=192, bias=True)
(norm1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
(classifier): Sequential(
(0): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(1): Linear(in_features=192, out_features=10, bias=True)
)
)
- Total params: 1,242,442
[Training infomation]
- Training duration on full training set: 19m 55s
- Training device: cuda on Kaggle's free P100, Thank you Google!
[Benchmarks on test set]
- Test loss: 0.7802
- Test accuracy: 73.24%
==================================================
|
ViT-B-16 的微调结果
| ==================================================
Results
==================================================
[Hyper parameters]
- Best LR: 0.000308
- Best epochs: 45 epochs
- Batch size: 128
[Model structure]
- Model type: ViT
- Model structure:
ViT_Cifar10(
(upsampler): Resize(size=(224, 224), interpolation=bilinear, max_size=None, antialias=True)
(vit): VisionTransformer(
(conv_proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(encoder): Encoder(
(dropout): Dropout(p=0.0, inplace=False)
(layers): Sequential(
(encoder_layer_0): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_1): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_2): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_3): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_4): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_5): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_6): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_7): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_8): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_9): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_10): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(encoder_layer_11): EncoderBlock(
(ln_1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(self_attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.0, inplace=False)
(ln_2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=3072, out_features=768, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
)
(ln): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
)
(heads): Sequential(
(head): Linear(in_features=768, out_features=10, bias=True)
)
)
)
- Total params: 7,690
[Training infomation]
- Training duration on full training set: 265m 15s
- Training device: cuda on Kaggle's free P100, Thank you Google!
[Benchmarks on test set]
- Test loss: 0.1402
- Test accuracy: 95.42%
==================================================
|
对 ViT 模型的解读和评述
本次实验仍然是从零训练+微调。从零训练使用展示的一个 nanoViT,微调使用的是 torchvision 提供的预训练权重 ViT_B_16_Weights.IMAGENET1K_V1,通过冻结骨干网络替换分类头的方式进行微调。
叫 nanoViT 是为了向 Karpathy 的 nanoGPT 致敬,其他网络都在卷花活的时候,Transformer 真的是大力出奇迹。
下面是 nanoViT 的结构示意,我们从宏观到微观来拆解。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef result fill:#45475a,stroke:#a6e3a1,stroke-width:2px,color:#cdd6f4;
classDef conv fill:#313244,stroke:#74c7ec,stroke-width:2px,color:#cdd6f4;
classDef transformer fill:#313244,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
%% Input Layer
subgraph Input["Input"]
A[("3@32×32")]
end
class Input input;
%% Patch Embedding
subgraph PatchEmbed["Patch Embedding"]
B["Conv2d<br> 3x192 x 2×2 / 2"]
C["Dropout<br> p=0.1"]
U["CLS token<br>192 dim vector"]
V[("contact")]
end
U --> V
A --> B --> V
V --> C
class PatchEmbed conv;
%% Positional Encoding
subgraph PosEnc["Postional Encoding"]
S["Parameter Matrix<br>(256+1) x 192<br>1 for CLS token"]
end
class PosEnc conv;
T["Dropout<br>p=0.1"]
D[("+")]
S --> D --> T
C -->|257 tokens or patches<br>embedded into 192 dim per patch| D
%% Transformer Encoder
subgraph TransformerEncoder["Transformer Encoder"]
E["Encoder Layer 1"]
F["Encoder Layer 2"]
G["Encoder Layer 3"]
H["Encoder Layer 4"]
end
T -->|257x192| E --> F --> G --> H
class TransformerEncoder transformer;
%% Extract [CLS] Token
I["Extract CLS token"]
H -->|257x192| I
%% Classification Head
subgraph Classifier["MLP Head"]
J["LayerNorm<br>192 dim"]
K["Linear<br>192x10"]
end
I -->|192 dim vector| J --> K
class Classifier box;
%% Output Layer
subgraph Output["Output"]
L[("10")]
end
K --> L
class Output output;
%% Styling
style A stroke-dasharray: 5 5
style L stroke:#a6e3a1,stroke-width:3px
这里利用卷积操作,将 3@32x32 的图像变成 192@16x16 的图像补丁,并将后两个维度展平,就得到 192x256 的矩阵,其中 256 是补丁的个数,192 是通道数(提取的特征数量),也就是每个补丁可以映射到 192 维的嵌入空间里面。选 192 是为了控制参数量在 1M 的数量级,其实应该更大的,具体可见下面的讨论。因此我们将矩阵转置为 256x192,也就是输入序列长度乘以嵌入维数,这就和 TrasformerEncoder 的要求匹配了。选择 2x2 的补丁一方面有受到 ViT 论文标题 An image is worth 16x16 words 的影响,毕竟 32 / 2 = 16,另一方面就是类比卷积神经网络的 3x3 卷积核,所以考虑在 2x2 和 4x4 中间选,因为先前测试过 4x4 的 patch_size 效果不如 2x2 好,于是就定下来是 2x2 了。
我们知道注意力矩阵不包含位置信息,所以需要位置编码来对不同位置的同一个 token 进行区分。ViT 的作者尝试了 1-D, 2-D 固定位置编码以及可学习的位置编码,效果都差不多,因此在这里使用可学习的位置编码。
但是由于我们需要对图像进行有监督分类,单纯对图像进行注意力操作是不会利用到任何标签信息的,所以还需要增加一个单独的 token,这个 token 用来捕获分类的结果。由于 TrasformerEncoder 不会改变输入的形状和位置关系,所以只需要在最后提取这个分类 token,并将其投影到 10 个类别上面即可实现端到端的学习。
下面是每一个 TrasformerEncoder 层的细节实现。值得注意的是两个残差连接,分别跨越了多头注意力模块和前馈神经网络模块。残差连接的作用之前已经详细阐述,此处不必多说。
这里的前馈神经网络实现和一般的 MLP head 不大一样。之前我们看到的 MLP head 都是漏斗型的,这里的 FFN 却是先升维再降维。因为此处 FFN 只是对拼接的多头注意力进行混合,不是压缩而是混合特征,因此需要在高维度区分特征,另一方面是,加入激活函数的 FFN 在升维的时候基本上不会因为 ReLU 或者 GELU 等其他激活函数的死连接而导致信息的损失(也就是降秩)。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef attention fill:#313244,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
classDef ffn fill:#313244,stroke:#74c7ec,stroke-width:2px,color:#cdd6f4;
%% Input
Input[("T×192")] --> Norm1["LayerNorm<br>192 dim"]
%% Multi-head Attention (8 heads)
subgraph SelfAttn["Multi-Head Attention"]
subgraph SA["Multi-Head Self Attention"]
Z1["Attention Head 0<br>Tx192->Tx24"]
Z2["......"]
Z3["Attention Head 7<br>Tx192->Tx24"]
end
Conc["Contact"]
Proj["Linear<br> 192x192"]
end
Norm1 --> Z1
Norm1 --> Z2
Norm1 --> Z3
Z1 --> Conc
Z2 --> Conc
Z3 --> Conc
Conc -->|Tx192| Proj
class SelfAttn attention;
%% Residual Connection 1
Proj --> Dropout1["Dropout: p=0.1"]
Dropout1 --> Add1(("+"))
Input --> Add1
%% Feed Forward Network
Add1 --> Norm2["LayerNorm<br>192 dims"]
subgraph FFN["Feed Forward Network"]
Linear1["Linear<br> 192x384"]
Dropout2["Dropout<br> p=0.1"]
Linear2["Linear<br> 384x192"]
end
Norm2 --> Linear1 --> Dropout2 --> Linear2
class FFN ffn;
%% Residual Connection 2
Linear2 --> Dropout3["Dropout<br>p=0.1"]
Dropout3 --> Add2(("+"))
Add1 --> Add2
%% Output
Add2 --> Output[("T×192")]
下面是多头自注意力每一个头的计算过程。其实我认为这里的头数类似于 conv2d 的通道数,衡量获取特征的多少;但是另一方面又被嵌入维度所限制,因为头数一多,分给每个头的投影维度就少了,信息也变少了。图上面的头数为 8 是我随意设置的,不过苏剑林有一个维度公式 n > 8.33 log N 对于注意力机制而言,N 就是预训练的序列长度 T 也就是 256,n 就是每个注意力头的维度,算出来要大于 \(8.33 \times \log_2 256\approx 66.64\) 才能够在每个头里面有效定位 token,所以这里的 num_heads 设置成 3 理论上看似会好一点。实际上回到之前的讨论,虽然维度够了,但是提取的特征不够,所以还是差一点,训练出来 loss = 0.9111 而 acc 很遗憾地只有 69.17%。所以回过头来,如果我们综合刚刚的讨论把 num_heads 设置到 8 而每个头的维度设置成 64……诶,这不就接近 ViT-B-16 使用的嵌入维度 768 嘛!
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef transform fill:#313244,stroke:#74c7ec,stroke-width:2px,color:#cdd6f4;
classDef attention fill:#313244,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
%% Input
subgraph Input["Input sequence"]
A[("T×embed_dim<br>T = 257<br>embed_dim = 192")]
end
class Input input;
%% Linear Transformations
subgraph Transformations["Linear proj for head_i"]
B["Projection matrix W_q_i<br> embed_dim×d_q = 192 x 24"]
C["Projection matrix W_k_i<br> embed_dim×d_k = 192 x 24"]
D["Projection matrix W_v_i<br> embed_dim×d_v = 192 x 24"]
end
A --> B
A --> C
A --> D
class Transformations transform;
%% Transformed Representations
E["Q_i = XW_q_i<br>T×d_q"]
F["K_i = XW_k_i<br>T×d_k"]
G["V_i = XW_v_i<br>T×d_v"]
B --> E
C --> F
D --> G
%% Attention Score Calculation
subgraph ScoreCalc["Attention Score"]
H["Q_i K_iᵀ <br>-------<br> √(d_k)"]
I["Softmax<br>Row-wise Norm"]
end
E --> H
F --> H
H -->|T x T| I
%% Output Calculation
subgraph OutputCalc["Attention Result"]
J["Attention_i = O_i V_i"]
end
I -->|Attention Score O_i<br>T x T| J
G --> J
%% Output
subgraph Output["Output for head_i"]
K[("T×d_v")]
end
J --> K
class Output output;
%% Styling
style A stroke-dasharray: 5 5
注意力这个词其实很形象,它通过计算得知“图像的哪一部分是重要的”。具体而言,由于我们需要的是自己添加的分类 token,所以让我们可视化一下这个 token 相对整张图片的注意力,也就能够得知“模型靠什么辨认出该标签”:

可以看到底层的注意力提取的信息偏向于明度信息,对较暗的如草坪阴影和狗头等具有较多关注度,后面的层关注点逐渐抽象,开始聚焦身体、四肢和尾巴等的特征。为何模型不再关注背景的草坪呢?考虑同时有两张图片,一张是猫在草坪上另一张是狗在草坪上,如果模型未能分割出草坪,则其就会将两者混为一谈,损失变大,若想降低损失,模型必须要捕获到两者的差别,即猫和狗身形或四肢等的差异,才能正确提取抽象特征进行分类。
总的 TransformerEncoder 计算时间复杂度为 \(O(T^2d+kd^2)\)。其中 \(T\) 是序列长度,\(d\) 是嵌入维度而 \(k\) 是注意力前的投影,注意力后的 FFN 等多个线性操作带来的倍率因子。在这个场景下序列长度不长,计算时间复杂度可以接受,高分辨率图片或者 LLM 里面的长上下文就难搞咯。
最后训练出来的 nanoViT 在 CIFAR-10 上获得了 73.24% 的准确率,和朴素 CNN 的准确率在一个水平。因为 Transformer 要大量数据投喂,所以不 Scale 怎么能行呢?
于是我选择一个大一点的,在 ImageNet 上已经预训练过的模型进行微调,也就是 ViT_B_16_Weights.IMAGENET1K_V1 这个模型权重,文档在此。这个神经网络基本上和刚刚的 nanoViT 完全一样,只不过扩大了对应的参数量,将编码器增加到了 12 个,而 FFN 层间激活函数使用了 GELU 而已。
微调的方法就是先把 32x32 的图像上采样到 224x224,就能和为 ImageNet 预训练的输入匹配了,然后冻结骨干网络,只需要替换分类头,训练好这个 MLP 分类分类头即可。由于这个模型的嵌入维度是 768,所以我们只需要对一个 7690 个参数进行微调就行了,按理说很快,不过……
由于笔者采用的是一个即插即用的端到端网络训练和评估框架,所以我想,定义模型的时候,__init__里面声明一下冻结骨干网,替换一下分类头,然后在forward里面上采样一下就行了。结果就是,对这 7690 个参数的微调,算上 5 次在训练子集上调参和一次全量数据的微调,一共花(浪费了)10 小时。所以大家不要直接复制上面的那个微调原理代码,会很浪费时间(和电,如果你使用云端收费 GPU 的话还很浪费钱)。
这是怎么回事呢?消耗时间的大头竟是前向传播也就是推理!实际上因为每一个 epoch 都需要对全部训练样本都完整走一遍前向过程,所以在找超参数的时候我重复进行了 \(\dfrac{1}{5}(52+34+31+91+65)=54.6\) 次全量数据的前向传播,但实际上我们已经冻结了骨干网络,所以只需要走一次全量数据前向传播,得到它们最后输出的 784 维编码向量即可!也就是说整个训练流程其实只需要十来分钟就可以完成的……
无论如何微调结果是相当棒的,准确率达到了 95% 以上,可以 在 osu! 里面拿到 S 评级了 和那些 SOTA 模型坐一桌了。
将图像利用 Patch 来转换成嵌入序列的方式很有意思!既然 Transformer 的注意力计算是 \(O(T^2d)\) 的,为何不请出序列数据处理(和线性注意力)的元祖,宝刀未老的 RNN 系列模型呢?(好吧 RNN 因为严重的梯度爆炸/消失问题尚能饭否还得打个问号,我们实际上使用 LSTM)
Patch based LSTM
Patch based LSTM 训练结果展示
训练使用的代码
| import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
class PatchEmbedding(nn.Module):
"""将图像分割为补丁并进行嵌入"""
def __init__(self, img_size=32, patch_size=2, in_channels=3, embed_dim=128):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
# 计算补丁数量
self.num_patches = (img_size // patch_size) ** 2
# 使用卷积层实现补丁嵌入 (等价于每个补丁应用一个卷积核)
self.proj = nn.Conv2d(
in_channels,
embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x: Tensor) -> Tensor:
# x形状: (batch_size, in_channels, img_size, img_size)
x = self.proj(x) # 输出形状: (batch_size, embed_dim, num_patches^(1/2), num_patches^(1/2))
x = x.flatten(2) # 输出形状: (batch_size, embed_dim, num_patches)
x = x.transpose(1, 2) # 输出形状: (batch_size, num_patches, embed_dim)
return x
class PatchLSTM(nn.Module):
def __init__(self, num_classes=10, img_size=32, patch_size=2,
embed_dim=128, hidden_size=256, num_layers=2,
bidirectional=True, dropout=0.1):
super(PatchLSTM, self).__init__()
# 使用卷积Patch嵌入层
self.patch_embed = PatchEmbedding(
img_size=img_size,
patch_size=patch_size,
in_channels=3,
embed_dim=embed_dim
)
# 计算patch数量
self.num_patches = (img_size // patch_size) ** 2
# 可学习的位置编码
self.pos_embed = nn.Parameter(torch.randn(1, self.num_patches, embed_dim))
# Dropout层
self.dropout = nn.Dropout(dropout)
# RNN主干网络 (使用LSTM)
self.rnn = nn.LSTM(
input_size=embed_dim,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=bidirectional,
dropout=dropout if num_layers > 1 else 0
)
# 分类头
rnn_output_size = hidden_size * 2 if bidirectional else hidden_size
self.classifier = nn.Sequential(
nn.LayerNorm(rnn_output_size),
nn.Linear(rnn_output_size, hidden_size),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_size, num_classes)
)
def forward(self, x):
# x形状: [B, 3, 32, 32]
# 1. 使用卷积层进行patch嵌入
patch_embeddings = self.patch_embed(x) # [B, num_patches, embed_dim]
# 2. 添加位置编码
patch_embeddings = patch_embeddings + self.pos_embed
# 3. 应用dropout
patch_embeddings = self.dropout(patch_embeddings)
# 4. 通过RNN处理序列
rnn_output, _ = self.rnn(patch_embeddings) # [B, num_patches, hidden_size * num_directions]
# 5. 取序列的最后一个输出(考虑了双向信息)
sequence_representation = rnn_output[:, -1, :] # [B, hidden_size * num_directions]
# 6. 分类
logits = self.classifier(sequence_representation)
return logits
def get_model_on_device():
# 创建模型实例
model = PatchLSTM(
num_classes=10, # CIFAR-10有10个类别
img_size=32, # CIFAR-10图像尺寸
patch_size=2, # 2x2的patch
embed_dim=128, # 嵌入维度
hidden_size=256, # RNN隐藏状态维度
num_layers=2, # RNN层数
bidirectional=True, # 使用双向RNN
dropout=0.1 # Dropout率
)
# 将模型移动到指定设备
return model.to(device)
|
Patch based LSTM 的训练结果
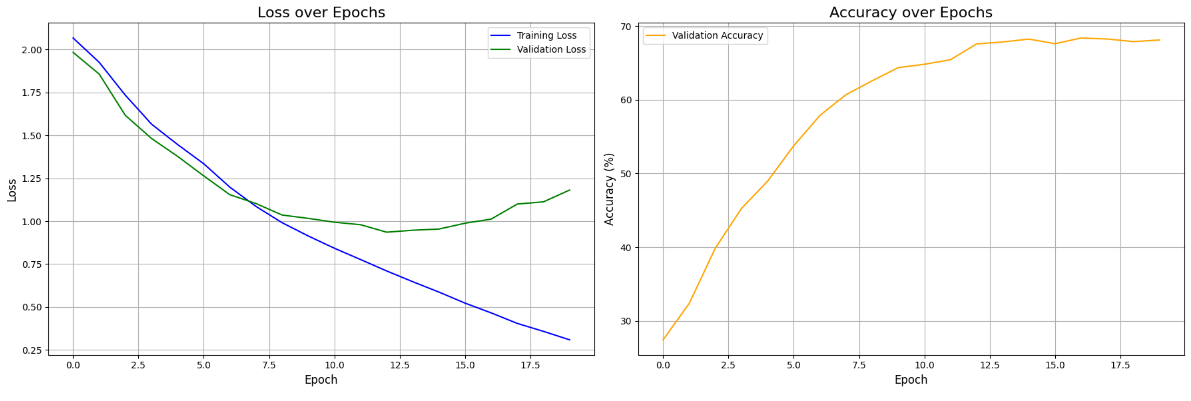
| ==================================================
Results
==================================================
[Hyper parameters]
- Best LR: 0.000425
- Best epochs: 20 epochs
- Batch size: 128
[Model structure]
- Model type: Patch based LSTM
- Model structure:
PatchRNN(
(patch_embed): PatchEmbedding(
(proj): Conv2d(3, 128, kernel_size=(2, 2), stride=(2, 2))
)
(dropout): Dropout(p=0.1, inplace=False)
(rnn): LSTM(128, 256, num_layers=2, batch_first=True, dropout=0.1, bidirectional=True)
(classifier): Sequential(
(0): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(1): Linear(in_features=512, out_features=256, bias=True)
(2): GELU(approximate='none')
(3): Dropout(p=0.1, inplace=False)
(4): Linear(in_features=256, out_features=10, bias=True)
)
)
- Total params: 2,536,842
[Training infomation]
- Training duration on full training set: 20m 27s
- Training device: cuda on Kaggle's free P100, Thank you Google!
[Benchmarks on test set]
- Test loss: 1.1816
- Test accuracy: 68.11%
==================================================
|
对 Patch based LSTM 的解读和评述
下面是总的模型结构图,使用了双层的双向 LSTM 作为编码器。其实双向仍然在提取位置关系上还是不够充分的,因为尽管图像 Patch 化了,其关联仍然不是纯线性序列的,所以还是加上了可学习的位置编码。这里的结构其实就是类似于把 nanoViT 的四个 TransformerEncoder 换成了基于 LSTM 的 RNN Encoder。至于为什么输入序列维度 128 过了这个编码器之后就变成 512 了呢?且看后面对这个编码器的拆解。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef conv fill:#313244,stroke:#74c7ec,stroke-width:2px,color:#cdd6f4;
classDef rnn fill:#313244,stroke:#f9e2af,stroke-width:2px,color:#cdd6f4;
%% Input Layer
subgraph Input["Input"]
A[("3@32×32")]
end
class Input input;
%% Patch Embedding
subgraph PatchEmbed["Patch Embedding"]
B["Conv2d<br> 3x128 x 2×2 / 2"]
end
A -->|Image| B
class PatchEmbed conv;
%% Positional Encoding
subgraph PosEnc["Positional Encoding"]
S["Parameter Matrix<br>256 x 128"]
end
class PosEnc conv;
D[("+")]
S --> D
B -->|256 patches<br>128 dim per patch| D
%% Dropout
T["Dropout<br>p=0.1"]
D --> T
%% RNN Encoder
subgraph RnnEncoder["RNN Encoder"]
E["2-Layer Bi-LSTM<br>hidden=256"]
end
T -->|256x128| E
class RnnEncoder rnn;
%% Extract Last Output
I["Extract Last<br>Time Step's Output"]
E -->|Sequence Output<br>256x512| I
%% Classification Head
subgraph Classifier["MLP Head"]
J["LayerNorm<br>512 dim"]
K["Linear<br>512x256"]
L["GELU"]
M["Dropout<br>p=0.1"]
N["Linear<br>256x10"]
end
I -->|Vector<br>512 dim| J --> K --> L --> M --> N
class Classifier box;
%% Output Layer
subgraph OutputLayer["Output"]
O[("10")]
end
N --> O
class OutputLayer output;
%% Styling
style A stroke-dasharray: 5 5
style O stroke:#a6e3a1,stroke-width:3px
下面是具体的编码器架构。输入序列是一个长度 256,嵌入维度 128 的序列,分别输入到正向和反向的 LSTM 里面,取输出也就是隐藏层状态 \(h\),在嵌入维度上拼到一起,得到新的序列,也就是隐藏层的维度 256,然后再过一遍正反向 LSTM,维度再翻一倍,得到输出的维度 512。所以双向 LSTM 输出维度是隐藏状态维度的两倍。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef rnn fill:#313244,stroke:#f9e2af,stroke-width:2px,color:#cdd6f4;
%% Input
Input[("Input Sequence<br>256 × 128")]
class Input input
%% Layer 1
subgraph LSTM_Layer_1 ["LSTM Layer 1"]
direction LR
Fwd1["Forward LSTM<br>h=256"]
Bwd1["Backward LSTM<br>h=256"]
end
Concat1["Concatenate<br>Outputs"]
Input --> Fwd1
Input --> Bwd1
Fwd1 --> |256x256| Concat1
Bwd1 --> |256x256| Concat1
%% Dropout between layers
Drop["Dropout<br>p=0.1"]
Concat1 --> |256x512| Drop
%% Layer 2
subgraph LSTM_Layer_2 ["LSTM Layer 2"]
direction LR
Fwd2["Forward LSTM<br>h=256"]
Bwd2["Backward LSTM<br>h=256"]
end
Concat2["Concatenate<br>Outputs"]
Drop --> Fwd2
Drop --> Bwd2
Fwd2 --> |256x256| Concat2
Bwd2 --> |256x256| Concat2
%% Output
Output[("Output Sequence<br>256 × 512")]
class Output output
Concat2 --> |256x512| Output
%% Styling
class LSTM_Layer_1,LSTM_Layer_2 rnn
下面是 LSTM 的具体结构。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef gate fill:#313244,stroke:#89dceb,stroke-width:2px,color:#cdd6f4;
classDef cell fill:#313244,stroke:#a6e3a1,stroke-width:2px,color:#cdd6f4;
classDef op fill:#45475a,stroke:#cdd6f4,stroke-width:1px,shape:circle;
classDef transform fill:#313244,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
classDef title fill:#1e1e2e,stroke:#cba6f7,stroke-width:1px,color:#cba6f7;
%% Inputs
subgraph Inputs
direction LR
Xt["Input x_t<br>dim: 128"]
Ht_1["Hidden h_t-1<br>dim: 256"]
end
Ct_1["Cell c_t-1<br>dim: 256"]
%% Concatenation
Concat["Concatenate [h_t-1, x_t]<br>dim: 256 + 128 = 384"]
Ht_1 --> Concat
Xt --> Concat
%% Linear Transformation
subgraph LinearProj ["Gate & Cell Candidate Projections"]
W["Linear <br>input: 384<br>output: 4 * 256 = 1024<br>(Effectively 4 parallel Linear(384, 256) layers)"]
end
Concat --> W
class LinearProj transform;
%% Gate Activations
subgraph GateActivations ["Gate Activations"]
direction LR
subgraph ForgetGate["Forget Gate"]
S_f["Sigmoid"]
end
subgraph InputGate["Input Gate"]
S_i["Sigmoid"]
end
subgraph CellCandidate["Cell Candidate"]
T_g["tanh"]
end
subgraph OutputGate["Output Gate"]
S_o["Sigmoid"]
end
end
W --> |Linear proj for f_t| S_f
W --> |Linear proj for i_t| S_i
W --> |Linear proj for g_t| T_g
W --> |Linear proj for o_t| S_o
%% Cell State Update
subgraph CellState["Cell State Update"]
Mul1("⊙")
Mul2("⊙")
Add("+")
end
subgraph state["States of this time step"]
Ct_1
Concat
end
S_f --> |f_t<br>dim: 256| Mul1
Ct_1 --> Mul1
S_i --> |i_t<br>dim: 256| Mul2
T_g --> |g_t<br>dim: 256| Mul2
Mul1 --> Add
Mul2 --> Add
Ct["New Cell c_t<br>dim: 256"]
Add --> Ct
%% Hidden State Update
subgraph HiddenState["Hidden State Update"]
T_c["tanh"]
Mul3("⊙")
end
Ct --> T_c
S_o --> |o_t<br>dim: 256| Mul3
T_c --> Mul3
Ht["New Hidden h_t<br>dim: 256"]
Mul3 --> Ht
%% Recurrent Connections to next time step
Ct ---> nCt_1
Ht ---> nHt_1
nXt_1 --> nHt_1
subgraph nip["Input of the next time step"]
nXt_1["Input x_t+1<br>dim: 256"]
Ht
end
subgraph nst["States of the next time step"]
nCt_1["Cell c_t<br>dim: 256"]
nHt_1["Concatenated vector<br>dim: 384"]
end
%% Styling
class Title title;
class Inputs,nip input;
class Ht,Ct output;
class GateActivations gate;
class CellState,HiddenState cell;
class Mul1,Mul2,Mul3,Add op;
可以看到每一个时间步下,先将输入和隐藏状态拼接,由这个 384 维的拼接向量经过一个 4 倍隐藏维度的投影层,很自然的就可以把投影向量分成四份。每一份是都对当前状态和当前隐藏状态的特征进行映射的向量。这些向量要负责结合细胞状态来控制状态的更新和输出。其实这一步很像优化器的流程,事实上已经有关于 RNN 和优化器的一些对比讨论了。
首先来看第一个投影向量 \(f_t\),经过 Sigmoid 激活后,将其与细胞状态 \(c_{t-1}\) 相乘,也就是通过 \(f_t\) 来控制哪些分量应该忘掉,也就是激活后得到 0 的位置。
既然有遗忘,那也需要记忆。这就交给 \(i_t\) 和 \(g_t\)。由于 \(i_t\) 是特征经过 Sigmoid 激活的结果,恒为正,因此可以作为纯输入的信息。而 \(g_t\) 经过的是 tanh 激活,有正有负,和 \(i_t\) 相乘之后,一方面可以说是增加网络的宽度,另一方面也对输入信息提供合理的抑制,防止其单调递增。最后和遗忘门的结果加起来,就可以得到新的细胞状态 \(c_t\) 了。这里的细胞状态通过门控决定自己应该保留多少、更新多少,作用就和朴素 RNN 的隐藏状态是一致的。
但是 LSTM 里面也出现了一个隐藏状态,按我的理解,其实 LSTM 区分细胞状态和隐藏状态是一种对 RNN 隐藏状态的功能解耦。因为一方面,隐藏状态要负责记忆先前的序列信息,另一方面,隐藏状态还要肩负起提取序列特征输出的作用,所以 LSTM 采用了细胞状态记忆序列信息,而和输入一起丢进来的那个所谓的隐藏状态,起到的就是提取特征的作用。何以见得?让我们看看输出的计算。
这里仍然是特征经过 Sigmoid 激活后得到向量 \(o_t\),然后需要和 tanh 激活后的新细胞状态相乘——也就是说,为了得到新的隐藏状态,需要参考目前的记忆,来选择性提取当前输入带来的特征。
因此 LSTM 也可以解决 RNN 的梯度爆炸/消失的问题。RNN 因为是对记忆的全量更新,很容易遗忘早期信息,同时也在这种全量更新上累积梯度,成了等比数列;而 LSTM 只不过引入门控来限制更新,就可以增强记忆力而缓解梯度问题。
当然最后训练出来一个参数量 2M 的 LSTM,还是没能打败 nanoViT。毕竟二维的注意力矩阵,对长距离/空间上的特征依赖效果必然好于仅靠一两个隐藏状态建模记忆力的 LSTM 好。不过,我们也没有必要勉强它,毕竟,图像任务从来都不是擅长序列建模的 RNN 的强项。至少我们证明了,在图像分类任务上使用 RNN 是可行的。
VAE
这里笔者使用了三种利用 VAE (准确说是 β-VAE)进行图像分类的方法, 让我们按照从夯到拉的顺序评鉴一下 思路各异:
- 在隐空间进行 K-means 聚类,按标签投票成为该聚类的标签。
- CVAE,即拼接图像和标签,再给隐空间加个标签维度,这样甚至可以带标签生成。
- 还是 CVAE 的思路,但是借用编码器的特征提取器,训练一个分类头,将分类损失缩放一个比例掺到总损失里面(或许可以叫 γ-C-β-VAE?),其实有点类似用 VAE 给编码器做正则化。
由于 CIFAR-10 的训练集风格差异很大且数据量也不够,所以在介绍将 VAE 接入分类任务之前,先让我们尝试一下 VAE 的本门功夫——图像生成。
动漫风格头像生成 a.k.a. 画老婆
本次使用的数据集是 Kaggle 上面的 Anime Face Dataset,是基于 Danbooru 的一个 63k 张图像的子集,但是 GitHub 上的数据貌似因为版权原因被拿下了。不过我本来一直都在 Kaggle 的 GPU 上面训练所以也没多大影响。
数据集是不带标签的 3@64x64 图像,下面是一些样本:

(第五排从左往右第三个是 galgame "Island" 的女主御原凛音的立绘,大家都来玩啊~ 现在知道为什么这个数据集在GitHub上因为版权问题被拿下了吧 )
我们现在的任务就是根据已经有的头像,画出新的头像。也就是 \(y=f(x)\) 其中 \(y\) 是我们的生成图片, \(x\) 是原始图片。为了避免乱生成,其实需要最小化 \(y\) 和 \(x\) 的偏差。——这不是 ResNet 干的活吗?因此在这里我们需要澄清一点:
我们并不是取学习某一张图片,而是所有训练图片构成的概率分布!了解了这个概率分布的形状之后,我们就可以在里面采样,得到生成的图片了。而 ResNet 只会把输入数据原样返回。
我们假设输入的数据为 \(x\) 而概率分布为 \(p(x)\),我们需要找到一个方式去(近似)描述 \(p(x)\)。由于数据维度很高,且维度之间有复杂的相互关联,因此直接寻找是相当复杂的,那怎么办呢?
诶,当我们需要在复杂任务里面找规律的时候,第一时间想到的是什么?降维!具体而言,就是考虑这个目标分布是输入通过编码再解码的结果,而编码的过程,就是对特征和规律进行降维、压缩、提取的过程:
\[
p(x)\approx q(x)=\int q(x|z)q(z)\mathrm d z
\]
这里,\(x\) 是输入,\(q(x)\) 是我们对目标函数 \(p(x)\) 的拟合尝试,\(z\) 是降维后的隐变量,\(q(z)\) 就是隐变量的分布,而 \(q(x|z)\) 就是从隐变量生成图片的解码器。这个式子很好理解,里面的等式就是全概率公式。
下面我们要解决这样几个问题:
- 怎么获取编码器,也就是从原始的图像得到隐变量的分布?
- 怎么衡量两个分布的近似程度来得到损失函数?
第一个问题比较核心,也涉及到 VAE 的生图风格,我们等会再聊。第二个问题,大家基本上都能脱口而出——使用 KL 散度不就行了吗。
但是这里如果计算 \(p(x)\) 和 \(q(x)\) 的 KL 散度,其实很不方便,因为一是这些式子都比较原子化拆不开就不好化简(更何况 \(p(x)\) 都不知道,没办法算),二是刚刚费力引入的 \(z\) 没用上。
因此我们考虑对联合分布 \(p(x,z)\) 和 \(q(x,z)\) 计算 KL 散度,也就是说利用隐变量相对 \(p\) 与 \(q\) 的关系:(推导略长但是不难,下面有 Hint)
\[
\begin{align*}
KL\left(p(x,z)||q(x,z)\right)&=\int\int p(x,z) \log \dfrac{p(x,z)}{q(x,z)} \mathrm d x \mathrm d z\\
&= \int\int p(x)p(z|x) \log\dfrac{p(x)p(z|x)}{q(x,z)} \mathrm d z \mathrm d x\\
&=\int p(x)[\int p(z|x)\log\dfrac{p(x)p(z|x)}{q(x,z)} \mathrm d z]\mathrm d x\\
&=\mathbb E_{x\sim p(x)}[\int p(z|x)[\log p(x) + \log p(z|x)- \log q(x,z)] \mathrm d z]\\
&=\mathbb E_{x\sim p(x)}[\log p(x)+\int p(z|x)\log\dfrac{p(z|x)}{q(z)q(x|z)}\mathrm d z]\\
&=\mathbb E_{x\sim p(x)}[\log p(x)-\int p(z|x)\log q(x|z)\mathrm d z+\int p(z|x)\log\dfrac{p(z|x)}{q(z)}\mathrm d z]\\
&=\mathbb E_{x\sim p(x)}[\log p(x)-\mathbb E_{z\sim p(z|x)}[\log q(x|z)]+\int p(z|x)\log\dfrac{p(z|x)}{q(z)}\mathrm d z]\\
&=\mathbb E_{x\sim p(x)}[\log p(x)-\mathbb E_{z\sim p(z|x)}[\log q(x|z)]+KL(p(z|x) || q(z))]\\
&=\mathbb E_{x\sim p(x)}[\log p(x)]+\mathbb E_{x\sim p(x)}[-\mathbb E_{z\sim p(z|x)}[\log q(x|z)]+KL(p(z|x) || q(z))]\\
&=\mathrm{Constant.}+\mathbb E_{x\sim p(x)}[-ELBO]
\end{align*}
\]
这就是我们得到的损失函数。推导时应用了期望的性质和条件概率公式以及 KL 散度的定义,第五行消掉第一项的 \(p(z|x)\) 是用的概率的归一化性质。里面的 \(ELBO\) 这个马甲的意思叫 Evidence Lower Bound,即证据下界,因为这一联合分布的 KL 散度恒大于之前提到的边际分布的 KL 散度,所以叫做下界,其实证据下界就是对近似程度的衡量,简单说就是要最大化的量。整个推导的目标很明确,尽量不要让含有 \(p\) 的函数参与到最后的式子里面,利用好已有的 \(q\) 相关的函数。而且要让结果靠近对“编码器”和“解码器”的损失计算。于是乎,我们只需要最大化 \(ELBO\) 即可。关于 \(ELBO\),可以拆开:
\[
\begin{align*}
ELBO&=\mathbb E_{z\sim p(z|x)}[\log q(x|z)]-KL(p(z|x) || q(z))
\end{align*}
\]
第一项的意思是是重构误差,衡量解码器 \(q(x|z)\) 的结果对原图 \(x\) 的差异程度;第二项的意思是衡量编码器对隐变量分布的近似程度。
实际上我们可以将两项解耦,来分配不同的权重,也就是可以写成
\[
\begin{align*}
ELBO&=\mathbb E_{z\sim p(z|x)}[\log q(x|z)]-\beta KL(p(z|x) || q(z))
\end{align*}
\]
这叫做 β-VAE,后面我们会看到这样做的理由和意义。
为了计算 \(ELBO\),\(q(x|z)\) 自然是对隐变量 \(z\) 解码到 \(x\) 上的神经网络,而 VAE 的作者对隐变量分布 \(q(z)\) 和编码器 \(p(z|x)\) 给了个很激进的方案:默认它们是正态分布!这似乎听起来有点理由但又有点武断,其实后面我们将会看到,对 VAE 而言,成也正态分布,败也正态分布。
具体而言,对 \(q(z)\) 我们可以直接假定为标准正态分布 \(N(0,I)\),但是 \(p(z|x)\) 是个条件分布,怎么搞呢?事实上回忆一下多元正态函数的定义:
\[
p(z|x)=\dfrac{\exp{\left(-0.5\left |\dfrac{z-\mu}{\sigma}\right |^2\right)}}{\prod \sqrt{2\pi\sigma_i^2}}
\]
这里的 \(\mu\) 和 \(\sigma\) 都是和隐变量 \(z\) 维度一致的向量,也就是说可以用神经网络来压缩!
那么 KL 散度项就可以很轻松解决了:
\[
\begin{align*}
KL &= \int p(z|x)\log\dfrac{p(z|x)}{q(z)}\mathrm d z\\
&=\mathbb{E}_{z\sim p(z|x)}[\log \dfrac{p(z|x)}{q(z)}]\\
&=\mathbb{E}_{z\sim p(z|x)}[\log\dfrac{\exp{\left(-0.5\left |\dfrac{z-\mu}{\sigma}\right |^2\right)}}{\prod \sqrt{2\pi\sigma_i^2}}\times \dfrac{\prod \sqrt{2\pi}}{\exp{(-0.5 |z|^2)}}]\\
&=\mathbb{E}_{z\sim p(z|x)}[0.5|z|^2-0.5\left |\dfrac{z-\mu}{\sigma}\right |^2-\sum \log \sigma_i]\\
&=\dfrac 12 \sum \sigma_i^2 +\mu_i^2-1-\log \sigma_i
\end{align*}
\]
最后一步使用了正态分布二阶矩的性质:\(\mathbb{E}[x^2]=\mu^2+\sigma^2\)。
对于重构误差项,我们可能会想到利用 MSE 来衡量重构误差,但是这样做是否有理论依据呢?事实上如果考虑解码器 \(q(x|z)\) 和编码器一样服从正态分布,也就是:
\[
\begin{align*}
\mathbb E_{z\sim p(z|x)}[\log q(x|z)]&=\mathbb E_{z\sim p(z|x)}[\log \dfrac{\exp{\left(-0.5\left |\dfrac{x-\mu'}{\sigma'}\right |^2\right)}}{\prod \sqrt{2\pi{\sigma'}_i^2}}]\\
&=-\dfrac{1}{2|\sigma'|^2}|x-\mu'|^2-\sum\log \sqrt{2\pi{\sigma'}_i^2}
\end{align*}
\]
这里的 \(\mu'\) 即解码的均值其实就是输出的图像的均值。如果取 \(\sigma'\) 是固定的向量,那就得到 MSE 了。事实上,这里 \(\sigma'\) 的大小估计就和 β-VAE 的思想等价,都是来调控两种损失的比例的。因此我们就估计出了最终的损失函数:
\[
\begin{align*}
\mathcal{L}&=-\mathbb E_{x\sim p(x)}[ELBO]\\
&=-\mathbb E_{x\sim p(x)}[\mathbb E_{z\sim p(z|x)}[\log q(x|z)]-\beta KL(p(z|x) || q(z))]\\
&=\mathbb E_{x\sim p(x)}[\dfrac{1}{2}|x-\mu'|^2-\beta\dfrac 12 \sum \sigma_i^2 +\mu_i^2-1-\log \sigma_i]\\
&=\mathbb E_{x\sim p(x)}[MSE -\beta KLD]\\
&=\dfrac 1n \sum_i^n (MSE_{x_i}-\beta KLD_{x_i})
\end{align*}
\]
最后一步,就是通过采样近似期望。实际上我们进行的是批量训练,因此,每次只需要对输入采样一个隐变量 \(z\) 即可。也就是说最终我们得到了可以计算的损失函数!
\[
\mathcal{L(x)}=MSE_{x}-\beta KLD_{x}
\]
但是还有一个问题:虽然这是可以计算的,但 \(\mu\) 和 \(\sigma\) 的值会随着参数的变化而变化,进而影响到分布 \(q(z)\),也就是说带参数的正态分布是无法直接进行微分来反向传播的。这一问题有一个很好的解决方案:重参数化。
也就是从分布 \(N(\mu,\sigma^2)\) 采样其实就是一个平移加缩放,只需要在标准分布 \(N(0,1)\) 里面采样 \(y\),然后计算 \(y'=\mu+\sigma y\) 就可以得到从分布 \(N(\mu,\sigma^2)\) 采样的结果了。由于线性变换可微,就可以交给优化器做更新了。
现在回顾一下整个 VAE 的训练流程:
- 输入 \(x\) 通过编码器得到两个和 \(z\) 维度一致的向量 \(\mu\) 和 \(\sigma\)。
- 在标准正态分布下采样向量 \(\epsilon\) 然后计算 \(z=\mu + \epsilon\odot\sigma\)。
- 将 \(z\) 输入到解码器得到重构图像 \(x'\)。
- 根据 \(\mu\)、\(\sigma\) 和 \(x\) 以及 \(x'\),使用损失函数 \(\mathcal{L(x)}=MSE_{x}-\beta KLD_{x}\) 计算梯度并反向传播更新参数。
如此,通往 VAE 的道路已经铺好,让我们编写代码吧。
加载数据集使用的代码
| import os
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.utils as vutils
import numpy as np
# 数据集所在的路径
DATA_DIR = '/kaggle/input/animefacedataset/images/'
# 定义超参数
IMAGE_SIZE = 64 # 图像将被调整到的大小
BATCH_SIZE = 256 # 每个批次加载的图像数量,最好和下面训练的 bs 一致
NUM_WORKERS = 6 # 加载数据的工作进程数,虽然 Kaggle 会报 warning 但是实测 6 比 4 好。
# 定义图像预处理/变换
# 1. Resize: 缩放到 IMAGE_SIZE
# 2. ToTensor: 转换为 PyTorch Tensor,并将像素值从 [0, 255] 归一化到 [0.0, 1.0]
# 3. Normalize: 将 [0.0, 1.0] 的数据标准化到 [-1.0, 1.0],这是训练 GAN 的标准做法
transform = transforms.Compose([
transforms.Resize(IMAGE_SIZE),
transforms.CenterCrop(IMAGE_SIZE),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
class AnimeFaceDataset(Dataset):
"""自定义动漫人脸数据集"""
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.image_files = [f for f in os.listdir(root_dir)]
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, self.image_files[idx])
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
return image
print("loading dataset")
# 实例化数据集
anime_dataset = AnimeFaceDataset(root_dir=DATA_DIR, transform=transform)
print(f"Dataset size: {len(anime_dataset)} pictures.")
# 实例化 DataLoader
dataloader = DataLoader(
dataset=anime_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS,
pin_memory=True
)
real_batch = next(iter(dataloader))
# 设置绘图
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title("Training Images")
grid = vutils.make_grid(real_batch[:64], padding=2, normalize=True)
plt.imshow(np.transpose(grid.cpu(), (1, 2, 0))) # 从 (C, H, W) 转为 (H, W, C)
plt.show()
|
默认一发 64 抽,可以看看抽出来的有没有认识的()
下面就可以愉快训练了。
训练使用的代码
| import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.utils import make_grid
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import os
config = {
"METHOD_NAME": "VAE",
"LATENT_DIM": 128,
"BATCH_SIZE": 256,
"EPOCHS": 30,
"LR": 1e-4,
"BETA": 1.5,
"DEVICE": "cuda" if torch.cuda.is_available() else "cpu",
"DATA_PATH": "./data",
"OUTPUT_PATH": "./output"
}
output_dir = os.path.join(config["OUTPUT_PATH"], config["METHOD_NAME"])
os.makedirs(output_dir, exist_ok=True)
print(f"Using device: {config['DEVICE']}")
print(f"Running with Beta = {config['BETA']}")
train_loader = dataloader
# --- 2. 模型定义 ---
class VAE(nn.Module):
def __init__(self, latent_dim):
super(VAE, self).__init__()
self.latent_dim = latent_dim
# Encoder (64x64 -> 8x8)
self.encoder_features = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True), nn.MaxPool2d(2, 2)
)
self.fc_mu = nn.Linear(256 * 8 * 8, latent_dim)
self.fc_log_var = nn.Linear(256 * 8 * 8, latent_dim)
# Decoder (latent_dim -> 64x64)
self.decoder_fc = nn.Linear(latent_dim, 256 * 8 * 8)
self.decoder_conv = nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 2, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1),
nn.Tanh() # 输出范围 [-1, 1],匹配数据归一化
)
def encode(self, x):
h = self.encoder_features(x)
h = h.view(h.size(0), -1)
return self.fc_mu(h), self.fc_log_var(h)
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = self.decoder_fc(z)
h = h.view(h.size(0), 256, 8, 8)
return self.decoder_conv(h)
def forward(self, x):
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
return self.decode(z), mu, log_var
# --- 3. 损失函数 ---
def vae_loss_function(recon_x, x, mu, log_var):
MSE = F.mse_loss(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return MSE, KLD
# 用于存储指标的字典
metrics = {
'MSE loss': [],
'KLD loss': [],
'Total loss': [],
}
# --- 4. 训练循环 ---
def train(model, train_loader, optimizer, epoch):
model.train()
total_loss, tot_mse, tot_kld = 0, 0, 0
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{config['EPOCHS']}")
for data in pbar:
data = data.to(config["DEVICE"])
optimizer.zero_grad()
recon_batch, mu, log_var = model(data)
mse_loss, kld_loss = vae_loss_function(recon_batch, data, mu, log_var)
loss = mse_loss + config["BETA"] * kld_loss
loss.backward()
optimizer.step()
total_loss += loss.item()
tot_mse += mse_loss.item()
tot_kld += kld_loss.item()
pbar.set_postfix(loss=loss.item() / len(data))
avg_loss = total_loss / len(train_loader.dataset)
avg_mse = tot_mse / len(train_loader.dataset)
avg_kld = tot_kld / len(train_loader.dataset)
metrics["Total loss"].append(avg_loss)
metrics["MSE loss"].append(avg_mse)
metrics["KLD loss"].append(avg_kld)
print(f'====> Epoch: {epoch+1} Average MSE loss:{avg_mse:.4f}, KLD loss:{avg_kld:.4f}, total loss: {avg_loss:.4f}')
# --- 5. 生成函数 ---
def generate_and_save_images(model, save_path, n_samples=64):
model.eval()
with torch.no_grad():
noise = torch.randn(n_samples, config["LATENT_DIM"]).to(config["DEVICE"])
generated_images = model.decode(noise).cpu()
grid = make_grid(generated_images, nrow=8, padding=2, normalize=True)
plt.figure(figsize=(8, 8))
plt.imshow(grid.permute(1, 2, 0))
plt.axis("off")
plt.title("Generated Images from VAE")
plt.savefig(save_path)
plt.show()
# --- 6. 训练指标绘图 ---
def loss_visualization():
# 训练完成后绘制指标图表
plt.figure(figsize=(10, 6))
plt.plot(metrics['MSE loss'], label='MSE Loss', color='blue')
plt.plot(metrics['KLD loss'], label='KL Divergence Loss', color='red')
plt.plot(metrics['Total loss'], label='Total Loss', color='green')
plt.title(f'MSE, KLD and total Loss, beta = {config["BETA"]}')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
# --- 主程序 ---
if __name__ == "__main__":
model = VAE(latent_dim=config["LATENT_DIM"]).to(config["DEVICE"])
optimizer = optim.Adam(model.parameters(), lr=config["LR"])
print("--- Training VAE Model ---")
for epoch in range(config["EPOCHS"]):
train(model, train_loader, optimizer, epoch)
print("\n--- Generating Images from Trained VAE ---")
gen_save_path = os.path.join(output_dir, "generated_images.png")
generate_and_save_images(model, gen_save_path)
loss_visualization()
|
这是 VAE 的总的架构,这里把 KL 取了个负号所以最后是加法:
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef conv fill:#313244,stroke:#74c7ec,stroke-width:2px,color:#cdd6f4;
classDef latent fill:#313244,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
classDef loss fill:#313244,stroke:#f2cdcd,stroke-width:2px,color:#cdd6f4;
%% Input
subgraph InputGraph["Input"]
A[("Image<br>3@64x64")]
end
class InputGraph input;
%% Encoder
subgraph Encoder["Encoder"]
B["Feature Extractor<br>map: 3@64x64→latent dim"]
end
A --> B
class Encoder conv;
%% Latent Space Distribution
subgraph LatentDistribution["Latent Distribution"]
mu["μ <br>latent dim"]
logvar["log(σ²)<br>latent dim"]
end
B -->|latent dim vector| mu
B -->|latent dim vector| logvar
class LatentDistribution latent;
%% Reparameterization Trick
subgraph ReparamTrick["Reparameterization"]
C["z = μ + ε * σ<br>ε~N(0,I)"]
end
mu --> C
logvar --> C
class ReparamTrick latent;
%% Decoder
subgraph Decoder["Decoder"]
D["Latent vector decoder"]
end
C --> |sample vector z<br>latent dim| D
class Decoder conv;
%% Output
subgraph OutputGraph["Output"]
E[("Reconstructed Image<br>3@64x64")]
end
D --> E
class OutputGraph output;
%% Loss Calculation
subgraph LossCalc["Loss Calculation"]
L["Loss = MSE + β * KLD"]
M["MSE"]
N["KLD"]
end
E --> |Reconstruction| M
A --> |Original| M
mu --> |Distribution| N
logvar --> |Distribution| N
M --> L
N --> L
class LossCalc loss;
其中,编码器使用三层的卷积神经网络,并使用了池化来缩小特征图,这也是“糊”的一部分原因,在后面的 GAN 复现中,我们采用了全卷积的架构,因为缩小特征图必不一定非要池化,还可以改变步长。下面是编码器的具体架构:
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef latent fill:#313244,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
classDef fc fill:#313244,stroke:#cba6f7,stroke-width:2px,color:#cdd6f4;
classDef convBlock fill:#1e1e2e,stroke:#89dceb,stroke-width:1px,color:#89dceb;
%% Input
Input[("Input Image<br>3@64x64")]
class Input input;
%% Encoder Block 1
subgraph EncoderBlock1 ["Encoder Block 1"]
direction LR
Conv1["Conv2d <br> 3x64 x 3x3 /1"]
BN1["BatchNorm2d<br>64"]
ReLU1["ReLU"]
Pool1["MaxPool2d<br>2x2 /2"]
Conv1 --> BN1 --> ReLU1 --> Pool1
end
%% Encoder Block 2
subgraph EncoderBlock2 ["Encoder Block 2"]
direction LR
Conv2["Conv2d <br> 64x128 x 3x3 /1"]
BN2["BatchNorm2d<br>128"]
ReLU2["ReLU"]
Pool2["MaxPool2d<br>2x2 /2"]
Conv2 --> BN2 --> ReLU2 --> Pool2
end
%% Encoder Block 3
subgraph EncoderBlock3 ["Encoder Block 3"]
direction LR
Conv3["Conv2d <br> 128x256 x 3x3 /1"]
BN3["BatchNorm2d<br>256"]
ReLU3["ReLU"]
Pool3["MaxPool2d<br>2x2 /2"]
Conv3 --> BN3 --> ReLU3 --> Pool3
end
%% Flatten and FC layers
Flatten["Flatten"]
FC_mu["Linear<br>16384 x latent dim"]
FC_logvar["Linear<br>16384 x latent dim"]
%% Outputs
mu["μ<br>latent dim"]
logvar["log(σ²)<br>latent dim"]
%% Connections
Input --> EncoderBlock1
EncoderBlock1 --> |64 @ 32x32| EncoderBlock2
EncoderBlock2 --> |128 @ 16x16| EncoderBlock3
EncoderBlock3 --> |256 @ 8x8| Flatten
Flatten --> |16384| FC_mu --> mu
Flatten --> |16384| FC_logvar --> logvar
%% Styling
class EncoderBlock1,EncoderBlock2,EncoderBlock3 convBlock;
class FC_mu,FC_logvar fc;
class mu,logvar latent;
解码器和编码器的配置基本上一致,只不过使用了反卷积。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef fc fill:#313244,stroke:#cba6f7,stroke-width:2px,color:#cdd6f4;
classDef deconvBlock fill:#1e1e2e,stroke:#a6e3a1,stroke-width:1px,color:#a6e3a1;
%% Input
Input[("Sample z<br>latent dim")]
class Input input;
%% FC and Reshape
FC_dec["Linear<br>latent_dim x 16384"]
Reshape["Reshape"]
%% Decoder Block 1
subgraph DecoderBlock1 ["Decoder Block 1"]
direction LR
ConvT1["ConvTranspose2d<br>256x128 x 4x4 x 2"]
BN1["BatchNorm2d"]
ReLU1["ReLU"]
ConvT1 --> BN1 --> ReLU1
end
%% Decoder Block 2
subgraph DecoderBlock2 ["Decoder Block 2"]
direction LR
ConvT2["ConvTranspose2d<br>128x64 x 4x4 x 2"]
BN2["BatchNorm2d"]
ReLU2["ReLU"]
ConvT2 --> BN2 --> ReLU2
end
%% Final Conv and Activation
ConvT3["ConvTranspose2d<br>64x3 x 4x4 x 2"]
Tanh["Tanh"]
%% Output
Output[("Reconstructed Image<br>3@64x64")]
%% Connections
Input --> FC_dec
FC_dec --> |16384| Reshape
Reshape --> |256 @ 8x8| DecoderBlock1
DecoderBlock1 --> |128 @ 16x16| DecoderBlock2
DecoderBlock2 --> |64 @ 32x32| ConvT3
ConvT3 --> Tanh --> Output
%% Styling
class FC_dec fc;
class DecoderBlock1,DecoderBlock2 deconvBlock;
class Output output;
经过一段时间的等待之后,就可以看到生成的图像了,有的还是挺像模像样的。让我们调整 β 多试几次:
|
β = 1.5 |
β = 1 |
β = 0.5 |
| 生成图像 |
 |
 |
 |
| 损失变化 |
 |
 |
 |
可以看到其实 MSE 和 KLD 是按下葫芦浮起瓢的关系,因为 MSE 对应解码器的重构误差,KLD 对应编码器的建模误差,因此两边都能得到有效的训练。
对比 β = 1.5 的情况,β = 1 时确实有一点点更清晰了,但是图片更脏了。网上很多讨论说降低 β 可以提升清晰度,其实这并不一定对。事实上我降低了 β 貌似可以进一步改善 MSE 损失提升重建相似度,但其实在这个训练数据下 MSE 损失相比于 KLD 损失更容易下降,所以可以看到 β = 1 相比 β = 1.5,MSE 虽然略有下降但是 KLD 涨了一大截。而 β = 0.5 的时候,KLD 直接就翻倍了。
可以看到,当 β 比较大的时候,图像倒是有鼻子有眼,就是很糊;β 比较小,图像又开始脏起来了,变得不可名状。
我们思考 β 的作用:β 可以衡量输出图像的方差,β 越大则 KL 散度项占比越大,这就对应增大重构误差的方差估计,也就是说大 β 会让编码器的输出尽可能平滑,从而导致图像能够找到所有人脸的共同特征,但是没法生成具体的精细特征,简单说就是糊;而小 β 对应的就是不那么糊的图片,但是一直被重构误差牵着走,虽然重构误差小能够让图像更清晰,但却也没法对输入进行特别有效的编码,从而导致特征混起来了,输出就会比较脏。
所以说朴素的 VAE 糊,主要还是因为这些原因:
- 对隐变量、编码器和解码器的建模太武断,既然为了推导使用了正态分布,就要吃这个带来的后果。
- 压缩太严重。建模时极其容易平滑掉图像的高频信息。
介绍了 VAE 的本门功夫——图像生成之后,我们来看看怎么拿 VAE 进行邪修,也就是做图像分类。
无监督聚类
第一个想法相当自然,既然我们使用隐变量分布 \(q(z)\) 来对原有图像做压缩之后的表征,那么我们只需要对每一个输入 \(x\),计算其对应的隐变量分布 \(q(z)\) 的均值 \(\mu\),就可以将输入压缩到隐空间内。按理说,这个空间是提取了 \(x\) 的特征信息的,因此在这个空间里面做无监督的聚类,就可以进行分类了。
具体而言,我们使用 K-means 作为聚类手段,对每个类别进行投票,得票最高的标签代表本类别的标签。最后,对得到的隐空间做 t-SNE 可视化。下面是结果:
|
β = 0.1 |
β = 1 |
β = 10 |
| 准确率 |
23.59% |
24.64% |
24.01% |
| t-SNE可视化 |
 |
 |
 |
| 生成图像 |
 |
 |
 |
准确率大概是 24% 左右,还是很合理的,因为标签信息只占了图像语义信息的一小部分,因此聚类得到的边界基本上是多种语义特征的混合(举例:我不仅可以按物体类别聚类,还可以按照背景色调聚类,既然没有标签带来的分类惩罚,我就可以随心所欲),自然不能和标签信息完全对应。比如说,截至本文写作时间,目前最强大的开源自监督视觉模型 DINOv3 在 ImageNet 上自监督聚类的准确率也只有 75% 左右。但是加上标签信息之后,准确率就可以突飞猛进了。
可以看到,β 基本上对准确率没有影响,因为我们是不带标签信息完全无监督地进行训练的,但是越大的 β 可视化出来的簇越集中,这就意味着增大 KL 散度项的权重,相当有利于数据降维压缩,但是对应图像也越糊,因为这一压缩过程是不可逆的,输出也被过度平滑了。
无监督聚类 VAE 使用的代码
| import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.manifold import TSNE
from tqdm import tqdm
import os
from scipy.stats import mode
# --- 1. 配置参数 ---
config = {
"METHOD_NAME": "VAE",
"LATENT_DIM": 128,
"NUM_CLUSTERS": 10,
"BATCH_SIZE": 128,
"EPOCHS": 30,
"LR": 1e-3,
"BETA": 0.1,
"DEVICE": "cuda" if torch.cuda.is_available() else "cpu",
"DATA_PATH": "./data",
"OUTPUT_PATH": "./output"
}
output_dir = os.path.join(config["OUTPUT_PATH"], config["METHOD_NAME"])
os.makedirs(output_dir, exist_ok=True)
print(f"Using device: {config['DEVICE']}")
print(f"Running with Beta = {config['BETA']}")
# --- 2. 数据加载 ---
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.CIFAR10(root=config["DATA_PATH"], train=True, transform=transform, download=True)
test_dataset = datasets.CIFAR10(root=config["DATA_PATH"], train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=config["BATCH_SIZE"], shuffle=True, pin_memory=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=config["BATCH_SIZE"], shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# --- 3. 模型定义: VAE ---
class VAE(nn.Module):
def __init__(self, latent_dim):
super(VAE, self).__init__()
self.latent_dim = latent_dim
self.encoder_features = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True), nn.MaxPool2d(2, 2)
)
self.fc_mu = nn.Linear(256 * 4 * 4, latent_dim)
self.fc_log_var = nn.Linear(256 * 4 * 4, latent_dim)
self.decoder_fc = nn.Linear(latent_dim, 256 * 4 * 4)
self.decoder_conv = nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 2, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1), nn.Sigmoid()
)
def encode(self, x):
h = self.encoder_features(x)
h = h.view(h.size(0), -1)
return self.fc_mu(h), self.fc_log_var(h)
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = self.decoder_fc(z)
h = h.view(h.size(0), 256, 4, 4)
return self.decoder_conv(h)
def forward(self, x):
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
return self.decode(z), x, mu, log_var
# --- 4. 损失函数 ---
def vae_loss_function(recon_x, x, mu, log_var):
MSE = F.mse_loss(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return MSE + config["BETA"] * KLD
# --- 5. 训练循环 ---
def train(model, train_loader, optimizer, epoch):
model.train()
total_loss = 0
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{config['EPOCHS']}")
for data, _ in pbar:
data = data.to(config["DEVICE"])
optimizer.zero_grad()
recon_batch, _, mu, log_var = model(data)
loss = vae_loss_function(recon_batch, data, mu, log_var)
loss.backward()
optimizer.step()
total_loss += loss.item()
pbar.set_postfix(loss=loss.item() / len(data))
avg_loss = total_loss / len(train_loader.dataset)
print(f'====> Epoch: {epoch+1} Average loss: {avg_loss:.4f}')
def calculate_and_show_accuracy(cluster_labels, true_labels):
cluster_map = {}
for i in range(config["NUM_CLUSTERS"]):
labels_in_cluster = true_labels[cluster_labels == i]
if len(labels_in_cluster) == 0:
cluster_map[i] = 0
continue
most_common_label = mode(labels_in_cluster, keepdims=False)[0]
cluster_map[i] = most_common_label
predicted_labels = np.array([cluster_map[c] for c in cluster_labels])
accuracy = np.mean(predicted_labels == true_labels)
print(f"Clustering Accuracy: {accuracy * 100:.2f}%")
print("\nCluster to Label Mapping:")
for i in range(config["NUM_CLUSTERS"]):
print(f" Cluster {i} -> '{classes[cluster_map[i]]}'")
return cluster_map
def cluster_and_visualize_kmeans(model, data_loader):
model.eval()
all_latents, all_true_labels = [], []
with torch.no_grad():
for data, labels in tqdm(data_loader, desc="Encoding data for clustering"):
data = data.to(config["DEVICE"])
mu, _ = model.encode(data)
all_latents.append(mu.cpu().numpy())
all_true_labels.append(labels.numpy())
all_latents = np.concatenate(all_latents, axis=0)
all_true_labels = np.concatenate(all_true_labels, axis=0)
print("Performing K-Means clustering...")
kmeans = KMeans(n_clusters=config["NUM_CLUSTERS"], random_state=42, n_init='auto')
cluster_labels = kmeans.fit_predict(all_latents)
cluster_map = calculate_and_show_accuracy(cluster_labels, all_true_labels)
print("Performing t-SNE...")
tsne = TSNE(n_components=2, random_state=42)
latents_2d = tsne.fit_transform(all_latents)
plt.figure(figsize=(8, 7))
plt.scatter(latents_2d[:, 0], latents_2d[:, 1], c=cluster_labels, cmap='tab10', s=10)
plt.title('VAE + K-Means Clustering Visualization')
plt.savefig(os.path.join(output_dir, "cluster_visualization.png"))
plt.show()
return kmeans, cluster_map
def generate_labeled_images_kmeans(model, kmeans, cluster_map, save_path, n_samples=5):
model.eval()
centers = torch.from_numpy(kmeans.cluster_centers_).float().to(config["DEVICE"])
fig, axes = plt.subplots(n_samples, config["NUM_CLUSTERS"], figsize=(12, 6))
fig.suptitle("Generated Samples per Cluster", fontsize=16)
with torch.no_grad():
for i in range(config["NUM_CLUSTERS"]):
center_i = centers[i].unsqueeze(0).repeat(n_samples, 1)
noise = torch.randn_like(center_i) * 0.5
samples = center_i + noise
generated_images = model.decode(samples).cpu()
label_name = classes[cluster_map[i]]
axes[0, i].set_title(f"Cluster {i}\n -> '{label_name}'")
for j in range(n_samples):
img = generated_images[j].permute(1, 2, 0).numpy()
axes[j, i].imshow(img)
axes[j, i].axis("off")
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.savefig(save_path)
plt.show()
if __name__ == "__main__":
model = VAE(latent_dim=config["LATENT_DIM"]).to(config["DEVICE"])
optimizer = optim.Adam(model.parameters(), lr=config["LR"])
print("--- Training VAE Model ---")
for epoch in range(config["EPOCHS"]):
train(model, train_loader, optimizer, epoch)
print("\n--- Clustering, Visualization, and Accuracy ---")
kmeans_model, cluster_to_label_map = cluster_and_visualize_kmeans(model, test_loader)
print("\n--- Generating Labeled Images ---")
gen_save_path = os.path.join(output_dir, "generated_labeled_images.png")
generate_labeled_images_kmeans(model, kmeans_model, cluster_to_label_map, gen_save_path)
|
CVAE
CVAE 即条件 VAE。CVAE 的目标本不是解决分类任务,而是利用标签来限定生成。这是本系列博客中,我们接触到的第一个文生图(T2I)模型。为此,首先需要输入带标签的训练数据——这个简单,只需要提取输入特征之后,拼接上标签向量即可,然后压缩到 \(\mu\) 和 \(\sigma\) 的分布上。然后解码器部分,对隐变量 \(z\) 也拼接上标签向量。就完了。
为何?我们最开始是对隐变量 \(z\) 进行随机采样的,这就意味着 \(z\) 不带有任何标签信息,如果我们给它加上标签信息,也就是说,我们给定标签 \(y\),要重建的是基于这个标签的条件分布 \(q(z|y)\)。对于编码器而言,因为标签 \(y\) 已知,所以直接利用联合条件分布 \(p(z|x,y)\) 来压缩到 \(z\) 上,而对解码器而言,也是一个联合的条件分布 \(q(x|z,y)\) 来从隐变量的条件分布来输出服从标签的条件分布。也就是下面的 \(ELBO\)。
\[
\begin{align*}
ELBO&=\mathbb E_{z\sim p(z|x)}[\log q(x|z,y)]-\beta KL(p(z|x,y) || q(z|y))
\end{align*}
\]
而分类方案就是对单个样本取所有标签,计算损失最小的那一个。
CVAE 利用标签的效率好不好呢?让我们看看下面的结果。
|
β = 0.1 |
β = 1 |
β = 10 |
| 准确率变化 |
 |
 |
 |
| 生成图像 |
 |
 |
 |
可以看到不管 β 调多少,基本上只能比随机基线的 10% 高一丢丢,说明标签在其中的贡献相当小!这说明模型基本上忽略了条件信息,基本上没有将其参与进图像重构中。换句话说,就是原来的 VAE 提供的信息和损失已经足够丰富,使得模型可以基本上直接无视分类的条件。事实上,这就是 VAE 的一个缺陷——当解码器过于强大,它会直接无视隐变量提供的信息来生成(类似于编码器退化掉,解码器变成 GAN 的生成器而重构误差项就是判别器),这被称作后验崩塌。
VQ-VAE 可以缓解这一问题。由于这不是本文的主题,仅在此简单介绍:VQ-VAE 抛弃了对隐空间 \(q(z)\) 的过强的正态分布假设,它过度平滑,因此考虑使用一个 d @ m x m 的张量(被称作码表),或者说是 \(m \times m\) 个排成矩阵的 \(d\) 维向量,来对隐空间做离散的建模,这样,CNN 输出的特征图 \(z\) 就可以和这个张量做映射,具体而言是抽取某个像素位置的所有通道特征得到一个 \(d\) 维向量,然后找到之前那个张量里面和这个 \(d\) 维向量最接近的那个 \(d\) 维向量,进行替换,也就是用码表去近似特征。然后替换后得到的特征图 \(z_q\) 就可以使用反卷积进行解码了。VQ-VAE 另一个创新就是在码表替换的时候,由于这一过程无法求梯度,于是作者设计了这样的损失项
\[
\mathcal L=|x-D(z+\mathrm{sg}[z_q-z])|^2 + \gamma |z-\mathrm{sg}[z_q]|^2+\beta |z_q-\mathrm{sg}[z]|^2
\]
这里 \(\mathrm{sg}[z]\) 的意思是,前向传播照常计算,反向传播丢弃梯度(stop gradient),这样前向传播的时候,就通过 \(z_q\) 进行生成,而反向传播的时候,重构误差依靠 \(z\) 计算梯度,而为了让梯度正常更新,又需要 \(z_q\) 尽量接近 \(z\),就有了后面两项,通过参数大小来分配码表和编码器的参数更新,这就对应 VAE 里面的 KLD,只不过这次我们没有强制对齐到正态分布了。
这里跑题挺远,扯回正题,下面是代码:
CVAE 的代码
| import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from tqdm import tqdm
import os
# --- 1. 配置参数 ---
config = {
"METHOD_NAME": "CVAE",
"LATENT_DIM": 128,
"NUM_CLASSES": 10,
"BATCH_SIZE": 128,
"EPOCHS": 30,
"LR": 1e-3,
"BETA": 0.1,
"DEVICE": "cuda" if torch.cuda.is_available() else "cpu",
"DATA_PATH": "./data",
"OUTPUT_PATH": "./output"
}
output_dir = os.path.join(config["OUTPUT_PATH"], config["METHOD_NAME"])
os.makedirs(output_dir, exist_ok=True)
print(f"Using device: {config['DEVICE']}")
print(f"Running with Beta = {config['BETA']}")
# --- 2. 数据加载 ---
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.CIFAR10(root=config["DATA_PATH"], train=True, transform=transform, download=True)
test_dataset = datasets.CIFAR10(root=config["DATA_PATH"], train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=config["BATCH_SIZE"], shuffle=True, pin_memory=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=config["BATCH_SIZE"], shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# --- 3. 模型定义: CVAE ---
class CVAE(nn.Module):
def __init__(self, latent_dim, num_classes):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.num_classes = num_classes
self.encoder_features = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True), nn.MaxPool2d(2, 2)
)
self.fc_mu = nn.Linear(256 * 4 * 4 + num_classes, latent_dim)
self.fc_log_var = nn.Linear(256 * 4 * 4 + num_classes, latent_dim)
self.decoder_fc = nn.Linear(latent_dim + num_classes, 256 * 4 * 4)
self.decoder_conv = nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 2, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1), nn.Sigmoid()
)
def encode(self, x, y_onehot):
h = self.encoder_features(x)
h_flat = h.view(h.size(0), -1)
h_combined = torch.cat([h_flat, y_onehot], dim=1)
return self.fc_mu(h_combined), self.fc_log_var(h_combined)
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z, y_onehot):
z_combined = torch.cat([z, y_onehot], dim=1)
h = self.decoder_fc(z_combined)
h = h.view(h.size(0), 256, 4, 4)
return self.decoder_conv(h)
def forward(self, x, y_onehot):
mu, log_var = self.encode(x, y_onehot)
z = self.reparameterize(mu, log_var)
recon_x = self.decode(z, y_onehot)
return recon_x, x, mu, log_var
# --- 4. 损失函数 ---
def cvae_loss_function(recon_x, x, mu, log_var):
MSE = F.mse_loss(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return MSE + config["BETA"] * KLD
# --- 5. 训练与测试循环 ---
def train(model, train_loader, optimizer, epoch):
model.train()
total_loss = 0
pbar = tqdm(train_loader, desc=f"Train Epoch {epoch+1}/{config['EPOCHS']}")
for data, labels in pbar:
data = data.to(config["DEVICE"])
labels_onehot = F.one_hot(labels, num_classes=config["NUM_CLASSES"]).float().to(config["DEVICE"])
optimizer.zero_grad()
recon_batch, _, mu, log_var = model(data, labels_onehot)
loss = cvae_loss_function(recon_batch, data, mu, log_var)
loss.backward()
optimizer.step()
total_loss += loss.item()
pbar.set_postfix(loss=loss.item() / len(data))
avg_loss = total_loss / len(train_loader.dataset)
print(f'====> Train Epoch: {epoch+1} | Avg Loss: {avg_loss:.4f}')
return avg_loss
def test(model, test_loader, epoch):
model.eval()
test_loss = 0
correct = 0
pbar = tqdm(test_loader, desc=f"Test Epoch {epoch+1}/{config['EPOCHS']}")
with torch.no_grad():
for data, labels in pbar:
data, labels = data.to(config["DEVICE"]), labels.to(config["DEVICE"])
batch_size = data.size(0)
# 存储每个样本在每个候选类别下的损失
losses_per_class = torch.zeros(batch_size, config["NUM_CLASSES"]).to(config["DEVICE"])
# 遍历所有可能的类别
for c in range(config["NUM_CLASSES"]):
# 为整个batch创建同一个类别的one-hot标签
class_labels = torch.full_like(labels, c)
class_onehot = F.one_hot(class_labels, num_classes=config["NUM_CLASSES"]).float()
# 计算损失
recon_batch, _, mu, log_var = model(data, class_onehot)
loss = cvae_loss_function(recon_batch, data, mu, log_var)
# VAE损失是整个batch的总和,我们需要每个样本的损失
# 这里用平均损失进行近似
losses_per_class[:, c] = loss / batch_size
# 找到每个样本损失最小的类别作为预测结果
pred = losses_per_class.argmin(dim=1)
correct += pred.eq(labels).sum().item()
# 计算测试损失时,我们使用真实标签
true_labels_onehot = F.one_hot(labels, num_classes=config["NUM_CLASSES"]).float()
recon_true, _, mu_true, log_var_true = model(data, true_labels_onehot)
test_loss += cvae_loss_function(recon_true, data, mu_true, log_var_true).item()
pbar.set_postfix(acc=f"{100. * correct / len(test_loader.dataset):.2f}%")
avg_loss = test_loss / len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'====> Test set | Avg Loss: {avg_loss:.4f} | Accuracy: {accuracy:.2f}%')
return avg_loss, accuracy
# --- 6. 可视化函数 ---
def visualize_latent_space(model, data_loader):
model.eval()
all_latents, all_labels = [], []
with torch.no_grad():
for data, labels in tqdm(data_loader, desc="Encoding data for visualization"):
data = data.to(config["DEVICE"])
labels_onehot = F.one_hot(labels, num_classes=config["NUM_CLASSES"]).float().to(config["DEVICE"])
mu, _ = model.encode(data, labels_onehot)
all_latents.append(mu.cpu().numpy())
all_labels.append(labels.numpy())
all_latents = np.concatenate(all_latents, axis=0)
all_labels = np.concatenate(all_labels, axis=0)
print("Performing t-SNE...")
tsne = TSNE(n_components=2, random_state=42, n_iter=300, n_jobs=-1)
latents_2d = tsne.fit_transform(all_latents)
plt.figure(figsize=(12, 10))
scatter = plt.scatter(latents_2d[:, 0], latents_2d[:, 1], c=all_labels, cmap='tab10', s=10)
plt.colorbar(scatter, ticks=range(10))
plt.title('t-SNE of Latent Space (Colored by True Class)')
plt.savefig(os.path.join(output_dir, "latent_space_true_labels.png"))
plt.show()
def generate_images_by_class(model, n_samples=5):
model.eval()
fig, axes = plt.subplots(n_samples, config["NUM_CLASSES"], figsize=(15, 8))
fig.suptitle("Generated Samples by Class", fontsize=16)
with torch.no_grad():
for class_idx in range(config["NUM_CLASSES"]):
class_onehot = F.one_hot(torch.tensor([class_idx]), num_classes=config["NUM_CLASSES"]).float()
class_onehot = class_onehot.repeat(n_samples, 1).to(config["DEVICE"])
z = torch.randn(n_samples, config["LATENT_DIM"]).to(config["DEVICE"])
generated_images = model.decode(z, class_onehot).cpu()
axes[0, class_idx].set_title(f"'{classes[class_idx]}'")
for sample_idx in range(n_samples):
img = generated_images[sample_idx].permute(1, 2, 0).numpy()
axes[sample_idx, class_idx].imshow(img)
axes[sample_idx, class_idx].axis("off")
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.savefig(os.path.join(output_dir, "generated_images_by_class.png"))
plt.show()
def plot_curves(train_losses, test_losses, test_accuracies):
epochs = range(1, len(train_losses) + 1)
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, 'bo-', label='Training Loss')
plt.plot(epochs, test_losses, 'ro-', label='Test Loss')
plt.title('Training and Test Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(epochs, test_accuracies, 'go-', label='Test Accuracy')
plt.title('Test Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.grid(True)
plt.suptitle('Training Metrics', fontsize=16)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.savefig(os.path.join(output_dir, "training_curves.png"))
plt.show()
# --- 主程序 ---
if __name__ == "__main__":
model = CVAE(latent_dim=config["LATENT_DIM"], num_classes=config["NUM_CLASSES"]).to(config["DEVICE"])
optimizer = optim.Adam(model.parameters(), lr=config["LR"])
train_losses, test_losses, test_accuracies = [], [], []
print("--- Training Pure CVAE Model for Classification ---")
for epoch in range(config["EPOCHS"]):
train_loss = train(model, train_loader, optimizer, epoch)
test_loss, test_acc = test(model, test_loader, epoch)
train_losses.append(train_loss)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
print("-" * 50)
print("\n--- Plotting Training Curves ---")
plot_curves(train_losses, test_losses, test_accuracies)
print("\n--- Visualizing Latent Space ---")
visualize_latent_space(model, test_loader)
print("\n--- Generating Images by Class ---")
generate_images_by_class(model)
|
CVAE 接分类头
最后一个方案比较工程,既然我们的编码器已经实现了一个特征提取器,为什么不直接在这个特征提取器上面训练分类头,最后将分类损失和 VAE 的损失汇总呢?也就是
\[
\mathcal L= \gamma CE-ELBO
\]
但是我们也可以换个视角,我们不将其看作是 CVAE 的魔改,而是一个 CNN 的魔改:对一个 CNN 接了个 CVAE 的支线,这样 \(-ELBO\) 就是对 CNN 原有交叉熵损失函数的正则化项!而这样的正则化极其有道理——我们并不是像 \(L_2\) 正则化一样约束参数大小,而是基于其图像本身和预测类别,来进一步约束特征提取器。当然,我们可以通过调节 \(\beta\) 和 \(\gamma\) 来控制正则化惩罚的强度。
这是目前三种尝试里面最好的效果,能够达到分类准确率 82% 以上,这还只是一个简单的 3 层 CNN,效果就已经接近之前从零训练的 ResNet-18 了。
|
β = 0.1 |
β = 1 |
β = 10 |
| 训练指标曲线 |
 |
 |
 |
| 生成图像 |
 |
 |
 |
带分类头的 CVAE 的训练代码
| import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from tqdm import tqdm
import os
# --- 1. 配置参数 ---
config = {
"METHOD_NAME": "CVAE_Classifier",
"LATENT_DIM": 128,
"NUM_CLASSES": 10,
"BATCH_SIZE": 128,
"EPOCHS": 30,
"LR": 1e-3,
"BETA": 0.1,
"GAMMA": 50,
"DEVICE": "cuda" if torch.cuda.is_available() else "cpu",
"DATA_PATH": "./data",
"OUTPUT_PATH": "./output"
}
output_dir = os.path.join(config["OUTPUT_PATH"], config["METHOD_NAME"])
os.makedirs(output_dir, exist_ok=True)
print(f"Using device: {config['DEVICE']}")
print(f"Running with Beta = {config['BETA']}, Gamma = {config['GAMMA']}")
# --- 2. 数据加载 ---
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.CIFAR10(root=config["DATA_PATH"], train=True, transform=transform, download=True)
test_dataset = datasets.CIFAR10(root=config["DATA_PATH"], train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=config["BATCH_SIZE"], shuffle=True, pin_memory=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=config["BATCH_SIZE"], shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# --- 3. 模型定义: CVAE + 分类器 ---
class CVAE(nn.Module):
def __init__(self, latent_dim, num_classes):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.num_classes = num_classes
# 编码器
self.encoder_features = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), nn.BatchNorm2d(64), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1), nn.BatchNorm2d(128), nn.ReLU(True), nn.MaxPool2d(2, 2),
nn.Conv2d(128, 256, 3, 1, 1), nn.BatchNorm2d(256), nn.ReLU(True), nn.MaxPool2d(2, 2)
)
# 分类头从图像特征直接进行分类
self.classifier = nn.Linear(256 * 4 * 4, num_classes)
# VAE部分
self.fc_mu = nn.Linear(256 * 4 * 4 + num_classes, latent_dim)
self.fc_log_var = nn.Linear(256 * 4 * 4 + num_classes, latent_dim)
# 解码器
self.decoder_fc = nn.Linear(latent_dim + num_classes, 256 * 4 * 4)
self.decoder_conv = nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 2, 1), nn.BatchNorm2d(128), nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1), nn.BatchNorm2d(64), nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1), nn.Sigmoid()
)
def encode(self, x, y_onehot):
# 提取图像特征
h = self.encoder_features(x)
h_flat = h.view(h.size(0), -1)
# --- 分类预测 ---
logits = self.classifier(h_flat)
# 将图像特征与标签信息拼接用于VAE
h_combined = torch.cat([h_flat, y_onehot], dim=1)
mu, log_var = self.fc_mu(h_combined), self.fc_log_var(h_combined)
return mu, log_var, logits
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z, y_onehot):
# 将潜在变量与标签信息拼接
z_combined = torch.cat([z, y_onehot], dim=1)
h = self.decoder_fc(z_combined)
h = h.view(h.size(0), 256, 4, 4)
return self.decoder_conv(h)
def forward(self, x, y_onehot):
mu, log_var, logits = self.encode(x, y_onehot)
z = self.reparameterize(mu, log_var)
recon_x = self.decode(z, y_onehot)
return recon_x, x, mu, log_var, logits
# --- 4. 损失函数 ---
def loss_function(recon_x, x, mu, log_var, logits, labels):
# VAE损失
MSE = F.mse_loss(recon_x, x, reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
vae_loss = MSE + config["BETA"] * KLD
# 分类损失
class_loss = F.cross_entropy(logits, labels, reduction='sum')
# 总损失
total_loss = vae_loss + config["GAMMA"] * class_loss
return total_loss, vae_loss, class_loss
# --- 5. 训练与测试循环 ---
def train(model, train_loader, optimizer, epoch):
model.train()
total_loss, total_vae_loss, total_class_loss = 0, 0, 0
correct = 0
total_samples = 0
pbar = tqdm(train_loader, desc=f"Train Epoch {epoch+1}/{config['EPOCHS']}")
for data, labels in pbar:
data, labels = data.to(config["DEVICE"]), labels.to(config["DEVICE"])
# 创建one-hot标签
labels_onehot = F.one_hot(labels, num_classes=config["NUM_CLASSES"]).float()
optimizer.zero_grad()
recon_batch, _, mu, log_var, logits = model(data, labels_onehot)
# 计算损失
t_loss, v_loss, c_loss = loss_function(recon_batch, data, mu, log_var, logits, labels)
t_loss.backward()
optimizer.step()
# 累加损失和正确分类数
total_loss += t_loss.item()
total_vae_loss += v_loss.item()
total_class_loss += c_loss.item()
pred = logits.argmax(dim=1, keepdim=True)
correct += pred.eq(labels.view_as(pred)).sum().item()
total_samples += len(data)
pbar.set_postfix(
loss=t_loss.item() / len(data),
acc=f"{100. * correct / total_samples:.2f}%"
)
avg_loss = total_loss / len(train_loader.dataset)
avg_vae_loss = total_vae_loss / len(train_loader.dataset)
avg_class_loss = total_class_loss / len(train_loader.dataset)
accuracy = 100. * correct / len(train_loader.dataset)
print(f'====> Train Epoch: {epoch+1} | Avg Loss: {avg_loss:.4f} | VAE Loss: {avg_vae_loss:.4f} | Class Loss: {avg_class_loss:.4f} | Accuracy: {accuracy:.2f}%')
return avg_loss, accuracy
def test(model, test_loader, epoch):
model.eval()
total_loss, total_vae_loss, total_class_loss = 0, 0, 0
correct = 0
with torch.no_grad():
for data, labels in test_loader:
data, labels = data.to(config["DEVICE"]), labels.to(config["DEVICE"])
labels_onehot = F.one_hot(labels, num_classes=config["NUM_CLASSES"]).float()
recon_batch, _, mu, log_var, logits = model(data, labels_onehot)
t_loss, v_loss, c_loss = loss_function(recon_batch, data, mu, log_var, logits, labels)
total_loss += t_loss.item()
total_vae_loss += v_loss.item()
total_class_loss += c_loss.item()
pred = logits.argmax(dim=1, keepdim=True)
correct += pred.eq(labels.view_as(pred)).sum().item()
avg_loss = total_loss / len(test_loader.dataset)
avg_vae_loss = total_vae_loss / len(test_loader.dataset)
avg_class_loss = total_class_loss / len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'====> Test set | Avg Loss: {avg_loss:.4f} | VAE Loss: {avg_vae_loss:.4f} | Class Loss: {avg_class_loss:.4f} | Accuracy: {accuracy:.2f}%')
return avg_loss, accuracy
# --- 6. 可视化函数 ---
def visualize_latent_space(model, data_loader):
model.eval()
all_latents, all_labels, all_preds = [], [], []
with torch.no_grad():
for data, labels in tqdm(data_loader, desc="Encoding data for visualization"):
data = data.to(config["DEVICE"])
labels_onehot = F.one_hot(labels, num_classes=config["NUM_CLASSES"]).float().to(config["DEVICE"])
mu, _, logits = model.encode(data, labels_onehot)
all_latents.append(mu.cpu().numpy())
all_labels.append(labels.numpy())
all_preds.append(logits.argmax(dim=1).cpu().numpy())
all_latents = np.concatenate(all_latents, axis=0)
all_labels = np.concatenate(all_labels, axis=0)
all_preds = np.concatenate(all_preds, axis=0)
print("Performing t-SNE...")
tsne = TSNE(n_components=2, random_state=42, n_iter=300, n_jobs=-1)
latents_2d = tsne.fit_transform(all_latents)
# 按真实标签可视化
plt.figure(figsize=(12, 10))
scatter = plt.scatter(latents_2d[:, 0], latents_2d[:, 1], c=all_labels, cmap='tab10', s=10)
plt.colorbar(scatter, ticks=range(10))
plt.title('t-SNE of Latent Space (Colored by True Class)')
plt.savefig(os.path.join(output_dir, "latent_space_true_labels.png"))
plt.show()
# 按预测标签可视化
plt.figure(figsize=(12, 10))
scatter = plt.scatter(latents_2d[:, 0], latents_2d[:, 1], c=all_preds, cmap='tab10', s=10)
plt.colorbar(scatter, ticks=range(10))
plt.title('t-SNE of Latent Space (Colored by Predicted Class)')
plt.savefig(os.path.join(output_dir, "latent_space_predicted_labels.png"))
plt.show()
def generate_images_by_class(model, n_samples=5):
model.eval()
fig, axes = plt.subplots(n_samples, config["NUM_CLASSES"], figsize=(15, 8))
fig.suptitle("Generated Samples by Class", fontsize=16)
with torch.no_grad():
for class_idx in range(config["NUM_CLASSES"]):
class_onehot = F.one_hot(torch.tensor([class_idx]), num_classes=config["NUM_CLASSES"]).float()
class_onehot = class_onehot.repeat(n_samples, 1).to(config["DEVICE"])
z = torch.randn(n_samples, config["LATENT_DIM"]).to(config["DEVICE"])
generated_images = model.decode(z, class_onehot).cpu()
axes[0, class_idx].set_title(f"'{classes[class_idx]}'")
for sample_idx in range(n_samples):
img = generated_images[sample_idx].permute(1, 2, 0).numpy()
axes[sample_idx, class_idx].imshow(img)
axes[sample_idx, class_idx].axis("off")
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.savefig(os.path.join(output_dir, "generated_images_by_class.png"))
plt.show()
# --- 绘制训练曲线的函数 ---
def plot_curves(train_losses, test_losses, train_accuracies, test_accuracies):
epochs = range(1, len(train_losses) + 1)
# 创建一个figure,包含两个子图
plt.figure(figsize=(14, 6))
# 子图1: 损失曲线
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, 'bo-', label='Training Loss')
plt.plot(epochs, test_losses, 'ro-', label='Test Loss')
plt.title('Training and Test Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
# 子图2: 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(epochs, train_accuracies, 'bo-', label='Training Accuracy')
plt.plot(epochs, test_accuracies, 'ro-', label='Test Accuracy')
plt.title('Training and Test Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.grid(True)
plt.suptitle('Training Metrics', fontsize=16)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.savefig(os.path.join(output_dir, "training_curves.png"))
plt.show()
if __name__ == "__main__":
model = CVAE(latent_dim=config["LATENT_DIM"], num_classes=config["NUM_CLASSES"]).to(config["DEVICE"])
optimizer = optim.Adam(model.parameters(), lr=config["LR"])
# 用于记录历史数据
train_losses, test_losses = [], []
train_accuracies, test_accuracies = [], []
print("--- Training CVAE with Classifier ---")
for epoch in range(config["EPOCHS"]):
train_loss, train_acc = train(model, train_loader, optimizer, epoch)
test_loss, test_acc = test(model, test_loader, epoch)
# 记录数据
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
print("-" * 50)
print("\n--- Plotting Training Curves ---")
plot_curves(train_losses, test_losses, train_accuracies, test_accuracies)
print("\n--- Visualizing Latent Space ---")
visualize_latent_space(model, test_loader)
print("\n--- Generating Images by Class ---")
generate_images_by_class(model)
|
GAN
拿 DC-GAN 画老婆
虽然推出 GAN 框架的方法有很多,比如博弈论(即一开始提出 GAN 的论文的思路)和能量视角等,不过,我个人更倾向于接着 VAE 的思路,用变分推断的框架去推导 GAN。
书接上回,我们知道 VAE 假定目标分布 \(p(x)\) 可以被两步拟合而成,也就是预期 \(p(x)\approx\int q(x|z)q(z)\mathrm dz\)。\(q(z)\) 即为隐变量分布,而 \(q(x|z)\) 是从采样生成图片的解码器——或者我们可以换个名字,叫做生成器,也就是 \(G(z)\)。
但是由于 VAE 引入的正态分布先验过多,导致朴素 VAE 出图很糊,于是我们考虑,至少和出图直接相关的生成器,可以改成非正态分布。怎么改呢?GAN 认为,可以直接建立随机变量 \(z\) 到 \(x\) 的一一对应!
\[
q(x|z)=\delta(x-G(z))
\]
这里用到了 Dirac's Delta 函数,就是要建立这种一一对应。由于我们没有强制假设正态性,所以现在也不好说 \(z\) 是隐变量,同时后验分布 \(p(z|x)\) 也不好推知了(在 VAE 里面,是一个正态分布)。至少我们没有强制用先验的正态分布,不会那么“糊”了。
我们知道无论如何变分推断的目的,是将不好推导的 \(KL(q(x)||p(x))\) 通过引入隐变量 \(y\),转化成更强也更容易推导的 \(KL(q(x,y)||p(x,y))\)。
GAN 认为,这个隐变量是一个二元的标签向量,也就是用来区分哪些是从 \(q(x|z)q(z)\) 生成的,哪些是 \(p(x)\) 本来的分布。也就是说:
\[
q(x,y)=\left\{
\begin{align*}
&\dfrac 12\ p(x),\ y = 1\\
&\dfrac 12\ q(x),\ y = 0
\end{align*}
\right.
\]
以及
\[
p(x,y)=p(y|x)p(x)
\]
这里的 \(\dfrac 12\) 主要是起一个归一化的作用。下面的式子是变分推断框架的一部分,我们在 VAE 的理论推导中就见过了,只不过,在 VAE 里面,它的意思是编码器,这里编的是什么码呢?是对图像来源进行判别得到的标签编码。也就是说,我们可以把 \(p(1|x)\) 看作一个分辨图像是否服从原分布的判别器,记作 \(D(x)\)
然后很机械地我们带入 KL 散度的计算式里面:
\[
\begin{align*}
KL(q(x,y)||p(x,y))&=\sum_y\int q(x,y) \log \dfrac{q(x,y)}{p(x,y)} \mathrm d x\\
&=\int q(x,1) \log \dfrac{q(x,1)}{p(x,1)} \mathrm d x+\int q(x,0) \log \dfrac{q(x,0)}{p(x,0)} \mathrm d x\\
&=\int \dfrac 12 p(x) \log \dfrac{\frac 12 p(x)}{p(1|x)p(x)}\mathrm dx+\int \dfrac 12 q(x) \log \dfrac{\frac 12 q(x)}{p(0|x)p(x)}\mathrm dx\\
&=-\log 2-\dfrac 12 \int p(x) \log p(1|x)\mathrm dx+\dfrac 12 \int q(x)\log \dfrac{q(x)}{p(0|x)p(x)}\mathrm dx\\
&=-\log 2-\dfrac 12 \int p(x) \log p(1|x)\mathrm dx+\dfrac 12 \int q(x)\log q(x)\mathrm dx-\dfrac 12 \int q(x)\log p(0|x)p(x)\mathrm dx
\end{align*}
\]
丢掉常数和系数。由于里面既有生成器 \(G\) 又有判别器 \(D\),因此,我们每一次优化分两步进行,也就是 EM 算法。
首先,固定生成器 \(G\) 也就是说现在生成的分布 \(q(x)\) 不变,同时真实分布 \(p(x)\) 不可能变;我们优化判别器 \(D\),写成期望形式:
\[
-\mathbb E_{x\sim p(x)}[\log D(x)]+\mathrm{Constant.}-\mathbb E_{x\sim q(x)}[\log (1-D(x))]-\int q(x) \log p(x) \mathrm dx
\]
第二项和第四项都是常数,我们由此得到了判别器的优化目标,也就是损失函数:
\[
\begin{align*}
\mathcal L_D&= - \mathbb E_{x\sim p(x)}[\log D(x)] - \mathbb E_{x\sim q(x)}[\log (1-D(x))]\\
&= - \mathbb E_{x\sim p(x)}[\log D(x)] - \mathbb E_{z\sim q(z)}[\log (1-D(G(z)))]
\end{align*}
\]
下面我们固定判别器,也就是 \(p(1|x)\) 固定,上式就剩下下面两项不是常数:
\[
\int q(x)\log q(x)\mathrm dx-\int q(x)\log p(0|x)p(x)\mathrm dx
\]
这里 \(p(x)\) 不知道,怎么办?事实上考虑一个好的判别器 \(D=p(1|x)\) 应该能完美区分来自 \(p(x)\) 的原始图像和来自 \(q(x)\) 的伪造图像,也就是说:
\[
D(x)=\dfrac{p(x)}{p(x)+\hat q(x)}
\]
就可以表征在 \(p(x)\) 和 \(q(x)\) 的混合下精准识别出真实样本。这里使用 \(\hat q(x)\) 是因为我们是分步进行的,这一步刚好要对生成器 \(G(z)=q(x|z)\) 更新,所以出现的 \(q(x)\) 必须是上一步的伪造分布。解出 \(p(x)\) 可得:
\[
p(x)=\hat q(x)\dfrac{D(x)}{1-D(x)}
\]
代入即可:
\[
\begin{align*}
\mathcal L_G&=\int q(x)\log q(x)\mathrm dx-\int q(x)\log p(0|x)p(x)\mathrm dx\\
&=\int q(x)\log q(x)\mathrm dx-\int q(x)\log [(1-D(x))\hat q(x)\dfrac{D(x)}{1-D(x)}]\mathrm dx\\
&=\int q(x)\log q(x)\mathrm dx-\int q(x)\log \hat q(x)\mathrm dx-\int q(x)\log D(x)\mathrm dx\\
&=-\mathbb E_{x\sim q(x)}[\log D(x)]+\int q(x)\log \dfrac{q(x)}{\hat q(x)}\mathrm dx\\
&=-\mathbb E_{z\sim q(z)}[\log D(G(z))]+KL(q(x)||\hat q(x))
\end{align*}
\]
事实上,\(KL(q(x)||\hat q(x))\) 可以说是对参数更新幅度的正则化约束,它要求理想情况下,\(q\) 的变动尽可能小。这其实就引出了各种操作,比如加上 BatchNorm,或者使用梯度惩罚等方法。当然本文的复现不涉及 WGAN,所以就不深挖,只讲一下后面会用到的谱归一化。
为了不训炸,控制参数更新量,我们应该对网络结构做出一定的光滑性约束。这样就引入了 Lipschitz 连续性的条件,也就是对于 \(f(x)\) 而言要求存在 \(K\) 使得
\[
|f(x_1)-f(x_2)|\leq K|x_1-x_2|
\]
对于单个线性层 \(f(x)=Wx\) 而言,\(K\) 其实衡量的是 \(W\) 能把 \(x\) 映射多“远”的能力,显然从几何意义上,我们可以对 \(W\) 做一个 SVD 也就是 \(W=U\Sigma V^\top\),由于 \(U\) 和 \(V\) 都是正交阵,\(K\) 其实就是对应缩放矩阵 \(\Sigma\) 里面最大的那个奇异值(这被称作该矩阵的谱范数)。那这不就好办了:对于每一层,我们都强制限制矩阵参数除以谱范数,就可以把每一层的 Lipschitz 条件控制到 \(K=1\) 因此整个网络的 \(K\) 也就限制到 \(1\) 了。这一操作称作谱归一化。
这样我们就从变分推断框架和 EM 算法得到了 GAN 的训练过程:
- 加载一批真实样本,计算 \(\mathbb E_{x\sim p(x)}[\log D(x)]\)
- 生成一批随机种子,然后交给 \(G\) 进行伪造生成后再判别,进而计算 \(\mathbb E_{z\sim q(z)}[\log (1-D(G(z)))]\) 和 \(\mathbb E_{z\sim q(z)}[\log D(G(z))]\)
- 计算判别器的损失并进行优化:\(\mathcal L_D= - \mathbb E_{x\sim p(x)}[\log D(x)] - \mathbb E_{z\sim q(z)}[\log (1-D(G(z)))]\)
- 计算生成器的损失并进行优化:\(\mathcal L_G=-\mathbb E_{z\sim q(z)}[\log D(G(z))]\)
下面就是整体的网络结构图了。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313444', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef gen fill:#313244,stroke:#a6e3a1,stroke-width:2px,color:#cdd6f4;
classDef disc fill:#313244,stroke:#f9e2af,stroke-width:2px,color:#cdd6f4;
classDef loss fill:#313244,stroke:#f2cdcd,stroke-width:2px,color:#cdd6f4;
classDef op fill:#313244,stroke:#89dceb,stroke-width:2px,color:#cdd6f4;
classDef step fill:#45475a,stroke:#a6e3a1,stroke-width:2px,color:#cdd6f4,radius:16px;
classDef addOp fill:#45475a,stroke:#cdd6f4,stroke-width:1px,shape:circle;
%% --- Data Generation ---
subgraph DataGen [Data Generation]
direction LR
Noise[("Latent Noise<br>z")] --> |latent_dim| G[("Generator<br>G")] --> |3 @ 64x64| FakeImg[("Fake Image<br>G(z)")]
RealImg[("Real Image<br>x")]
end
%% --- Discriminator Update Phase ---
subgraph Phase1 [Update Discriminator]
direction LR
D1[("Discriminator<br>D")]
subgraph LossCalcD [Loss Calculation]
Loss_D_Fake["Fake loss =<br>-E[log(1-D(G(z)))]"]
Loss_D_Real["Real loss =<br>-E[log D(x)]"]
Add_D_Loss[(+)]
Loss_D_Real --> Add_D_Loss
Loss_D_Fake --> Add_D_Loss
end
Add_D_Loss --> L_D["D loss =<br> Real loss + Fake loss"]
end
%% --- Generator Update Phase ---
subgraph Phase2 [Update Generator]
direction LR
D2[("Discriminator<br>D")]
Loss_G["G loss =-E[log D(G(z))]"]
end
%% --- Connecting the Phases ---
%% Connections for Discriminator training
Detach["Detach<br>Gradient"]
FakeImg --> Detach --> |3 @ 64x64| D1 -- "Score D(G(z))" --> Loss_D_Fake
FakeImg --> |3 @ 64x64| D2 -- "Score D(G(z))" --> Loss_G
RealImg --> |3 @ 64x64| D1 -- "Score D(x)" --> Loss_D_Real
%% Connection for Generator training
%% Set flow from left to right
%% Styling
class G gen;
class D1,D2 disc;
class Detach op;
class Add_D_Loss addOp;
class Noise,RealImg input;
class Loss_D_Real, Loss_D_Fake;
class Step_D,Step_G,Backward_D,Backward_G step;
需要注意的是,在对判别器计算损失并更新的时候,有一个 detach 的操作,这就是防止梯度回传到生成器。生成器有自己的损失函数用来更新。其他的部分和刚刚推导的无异。
这个图还有一个值得一提的点:生成器的梯度完全由判别器回传而来,也就是说有可能会发生之前在 VAE 里面提到的后验崩塌问题,即判别器过于强大,导致无法向生成器回传梯度。有一个巧妙的训练策略可以缓解这个问题:TTUR (Two Time-scale Update Rule),也就是给生成器更高的学习率,让它在判别器尚未充分强大的时候先变强。可以看到无论是 TTUR 还是谱归一化,抑或是理论里面推导到的 KL 散度项,都是在防止判别器太快地变得过强。
下面是生成器模块。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#f5c2e7,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef deconvBlock fill:#1e1e2e,stroke:#a6e3a1,stroke-width:1px,color:#a6e3a1;
%% Input
Input[("Latent Vector z<br>latent_dim")]
Reshape["Reshape to<br>latent_dim@1x1"]
%% Upsample Block 1
subgraph UpsampleBlock1 ["Upsample Block 1"]
direction LR
ConvTranspose2d1["ConvTranspose2d<br> latent_dim x 512 x 4x4 / 1"]
BN1["BatchNorm2d"]
ReLU1["ReLU"]
ConvTranspose2d1 --> BN1 --> ReLU1
end
%% Upsample Block 2
subgraph UpsampleBlock2 ["Upsample Block 2"]
direction LR
ConvTranspose2d2["ConvTranspose2d<br>512x256 x 4x4 / 2"]
BN2["BatchNorm2d"]
ReLU2["ReLU"]
ConvTranspose2d2 --> BN2 --> ReLU2
end
%% Upsample Block 3
subgraph UpsampleBlock3 ["Upsample Block 3"]
direction LR
ConvTranspose2d3["ConvTranspose2d<br>256x128 x 4x4 / 2"]
BN3["BatchNorm2d"]
ReLU3["ReLU"]
ConvTranspose2d3 --> BN3 --> ReLU3
end
%% Upsample Block 4
subgraph UpsampleBlock4 ["Upsample Block 4"]
direction LR
ConvTranspose2d4["ConvTranspose2d<br>128x64 x 4x4 / 2"]
BN4["BatchNorm2d"]
ReLU4["ReLU"]
ConvTranspose2d4 --> BN4 --> ReLU4
end
%% Final Conv and Activation
ConvTranspose2d5["ConvTranspose2dranspose2d<br>64x3 x 4x4 / 2"]
Tanh["Tanh"]
Output[("Generated Image<br>3@64x64")]
%% Connections
Input --> Reshape
Reshape --> UpsampleBlock1
UpsampleBlock1 --> |512 @4x4| UpsampleBlock2
UpsampleBlock2 --> |256 @8x8| UpsampleBlock3
UpsampleBlock3 --> |128 @16x16| UpsampleBlock4
UpsampleBlock4 --> |64 @32x32| ConvTranspose2d5
ConvTranspose2d5 --> Tanh --> Output
%% Styling
class Input input;
class Output output;
class UpsampleBlock1,UpsampleBlock2,UpsampleBlock3,UpsampleBlock4 deconvBlock;
下面是判别器模块。
%%{init: {'theme': 'dark', 'themeVariables': { 'darkMode': true, 'primaryColor': '#1e1e2e', 'edgeLabelBackground':'#313244', 'tertiaryColor': '#181825'}}}%%
graph LR
%% Styling definitions
classDef box fill:#313244,stroke:#cdd6f4,stroke-width:2px,color:#cdd6f4,radius:8px;
classDef input fill:#585b70,stroke:#89b4fa,stroke-width:2px,color:#cdd6f4;
classDef output fill:#313244,stroke:#f38ba8,stroke-width:2px,color:#cdd6f4;
classDef convBlock fill:#1e1e2e,stroke:#f9e2af,stroke-width:1px,color:#f9e2af;
%% Input
Input[("Input Image<br>3@64x64")]
%% Downsample Block 1
subgraph DownsampleBlock1 ["Downsample Block 1"]
direction LR
Conv1["Conv2d<br>3x64 x 4x4 / 2"]
LReLU1["LeakyReLU(0.2)"]
Conv1 --> LReLU1
end
%% Downsample Block 2
subgraph DownsampleBlock2 ["Downsample Block 2"]
direction LR
Conv2["Conv2d<br>64x128 x 4x4 / 2"]
BN2["BatchNorm2d"]
LReLU2["LeakyReLU(0.2)"]
Conv2 --> BN2 --> LReLU2
end
%% Downsample Block 3
subgraph DownsampleBlock3 ["Downsample Block 3"]
direction LR
Conv3["Conv2d<br>128x256 x 4x4 / 2"]
BN3["BatchNorm2d"]
LReLU3["LeakyReLU(0.2)"]
Conv3 --> BN3 --> LReLU3
end
%% Downsample Block 4
subgraph DownsampleBlock4 ["Downsample Block 4"]
direction LR
Conv4["Conv2d<br>256x512 x 4x4 / 2"]
BN4["BatchNorm2d"]
LReLU4["LeakyReLU(0.2)"]
Conv4 --> BN4 --> LReLU4
end
%% Final Conv and Activation
Conv5["Conv2d<br>512x1 x 4x4 / 4"]
Sigmoid["Sigmoid"]
Output[("Output Probability<br>Scalar")]
%% Connections
Input --> DownsampleBlock1
DownsampleBlock1 --> |64 @32x32| DownsampleBlock2
DownsampleBlock2 --> |128 @16x16| DownsampleBlock3
DownsampleBlock3 --> |256 @8x8| DownsampleBlock4
DownsampleBlock4 --> |512 @4x4| Conv5
Conv5 --> |1 @1x1| Sigmoid --> Output
%% Styling
class Input input;
class Output output;
class DownsampleBlock1,DownsampleBlock2,DownsampleBlock3,DownsampleBlock4 convBlock;
可见,这里的生成器和判别器都是全卷积网络,并且都使用了 BatchNorm2d 来稳定梯度。全卷积的作用在于不会因为池化的降采样而损失细节。
下面放出代码:
训练 DC-GAN 使用的代码
| import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.utils import make_grid, save_image
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import os
torch.backends.cudnn.benchmark = True
config = {
"METHOD_NAME": "DC-GAN",
"LATENT_DIM": 128,
"BATCH_SIZE": 256,
"EPOCHS": 50,
"LR": 2e-4,
"BETA1": 0.5, # Adam优化器的beta1参数
"DEVICE": "cuda" if torch.cuda.is_available() else "cpu",
"DATA_PATH": "./data",
"OUTPUT_PATH": "./output"
}
output_dir = os.path.join(config["OUTPUT_PATH"], config["METHOD_NAME"])
os.makedirs(output_dir, exist_ok=True)
print(f"Using device: {config['DEVICE']}")
train_loader = dataloader
class Generator(nn.Module):
def __init__(self, latent_dim):
super(Generator, self).__init__()
self.latent_dim = latent_dim
self.main = nn.Sequential(
nn.ConvTranspose2d(latent_dim, 512, 4, 1, 0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
input = input.view(-1, self.latent_dim, 1, 1)
return self.main(input)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input).view(-1, 1)
# --- 3. 初始化模型和优化器 ---
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
# --- 4. 训练循环 ---
def train(generator, discriminator, train_loader, g_optimizer, d_optimizer, epoch):
generator.train()
discriminator.train()
real_label = 1.0
fake_label = 0.0
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{config['EPOCHS']}")
d_losses = []
g_losses = []
for i, data in enumerate(pbar):
# 训练判别器
# 使用真实图像
real_images = data.to(config["DEVICE"])
batch_size = real_images.size(0)
label = torch.full((batch_size, 1), real_label, dtype=torch.float, device=config["DEVICE"])
discriminator.zero_grad()
output = discriminator(real_images)
errD_real = F.binary_cross_entropy(output, label)
errD_real.backward()
D_x = output.mean().item()
# 使用生成图像
noise = torch.randn(batch_size, config["LATENT_DIM"], device=config["DEVICE"])
fake_images = generator(noise)
label.fill_(fake_label)
output = discriminator(fake_images.detach())
errD_fake = F.binary_cross_entropy(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
d_optimizer.step()
# 训练生成器
generator.zero_grad()
label.fill_(real_label) # 生成器希望判别器将假图像判断为真
output = discriminator(fake_images)
errG = F.binary_cross_entropy(output, label)
errG.backward()
D_G_z2 = output.mean().item()
g_optimizer.step()
# 记录损失
d_losses.append(errD.item())
g_losses.append(errG.item())
# 更新进度条
if i % 50 == 0:
pbar.set_postfix({
'D_loss': errD.item(),
'G_loss': errG.item(),
'D(x)': D_x,
'D(G(z))': f"{D_G_z1:.4f}/{D_G_z2:.4f}"
})
return np.mean(d_losses), np.mean(g_losses)
# --- 5. 生成函数 ---
def generate_and_save_images(generator, save_path, n_samples=64):
generator.eval()
with torch.no_grad():
noise = torch.randn(n_samples, config["LATENT_DIM"], device=config["DEVICE"])
generated_images = generator(noise).cpu()
grid = make_grid(generated_images, nrow=8, padding=2, normalize=True)
plt.figure(figsize=(8, 8))
plt.imshow(grid.permute(1, 2, 0))
plt.axis("off")
plt.title("Generated Images from DC-GAN")
plt.savefig(save_path)
plt.close()
# 同时保存图像文件
save_image(generated_images, os.path.join(output_dir, f"generated_samples.png"), nrow=8, normalize=True)
# --- 6. 训练指标绘图 ---
def loss_visualization(d_losses, g_losses):
plt.figure(figsize=(10, 6))
plt.plot(d_losses, label='Discriminator Loss', color='blue')
plt.plot(g_losses, label='Generator Loss', color='red')
plt.title('DC-GAN Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.savefig(os.path.join(output_dir, "training_loss.png"))
plt.close()
# --- 主程序 ---
if __name__ == "__main__":
# 初始化模型
generator = Generator(latent_dim=config["LATENT_DIM"]).to(config["DEVICE"])
discriminator = Discriminator().to(config["DEVICE"])
# 应用权重初始化
generator.apply(weights_init)
discriminator.apply(weights_init)
# 初始化优化器
g_optimizer = optim.Adam(generator.parameters(), lr=config["LR"], betas=(config["BETA1"], 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=config["LR"], betas=(config["BETA1"], 0.999))
# 用于存储损失
d_losses = []
g_losses = []
print("--- Training DC-GAN Model ---")
for epoch in range(config["EPOCHS"]):
d_loss, g_loss = train(generator, discriminator, train_loader, g_optimizer, d_optimizer, epoch)
d_losses.append(d_loss)
g_losses.append(g_loss)
# 每5个epoch保存一次生成图像
if (epoch + 1) % 5 == 0:
gen_save_path = os.path.join(output_dir, f"generated_images_epoch_{epoch+1}.png")
generate_and_save_images(generator, gen_save_path)
torch.save(generator.state_dict(), os.path.join(output_dir, f"generator_{epoch+1}.pth"))
print("\n--- Generating Images from Trained DC-GAN ---")
gen_save_path = os.path.join(output_dir, "final_generated_images.png")
generate_and_save_images(generator, gen_save_path)
# 保存模型
torch.save(generator.state_dict(), os.path.join(output_dir, "generator.pth"))
torch.save(discriminator.state_dict(), os.path.join(output_dir, "discriminator.pth"))
# 绘制损失曲线
loss_visualization(d_losses, g_losses)
|
跑了 50 个 Epoch,损失曲线如下:

生成的图像随着 Epoch 变化如下:
| Epoch |
5 |
10 |
20 |
30 |
40 |
50 |
| 生成图像 |
 |
 |
 |
 |
 |
 |
50 个 Epoch 后的图像:
可以看到损失下降的同时,图像也越来越有模有样,同时也不“糊”了。
为了演示这个模型,我做了一个 demo,就部署在本博客上面:老婆生成器。推理使用的是 TensorFlow.js,完全在网页端进行的推理。加载模型需要一段时间,因为训练用图像都是 64x64 的,因此不会吃太多性能。
下面让我们看看怎么用 GAN 做分类吧。
AC-GAN 分类
AC-GAN 是我们遇到的第二个 T2I 模型。其核心思想和 CVAE 差不多:首先在采样生成的时候,同时拼接一个标签信息,最后在判别的时候,在输出真伪概率的同时,也输出分类结果。这样,通过人为控制标签,就可以实现条件生成。对于损失函数,加上分类损失即可。
\[
\begin{align*}
\mathcal L_D=& - \mathbb E_{x\sim p(x)}[\log D_{\mathrm{score}}(x)] + CE(D_{\mathrm{tag}}(x)||\mathrm{real\ tag}) \\&- \mathbb E_{z\sim q(z)}[\log (1-D_{\mathrm{score}}(G(z)))] + CE(D_{\mathrm{tag}}(G(z))||\mathrm{fake\ tag})
\end{align*}
\]
\[
\mathcal L_G=-\mathbb E_{z\sim q(z)}[\log D_{\mathrm{score}}(G(z))]+ CE(D_{\mathrm{tag}}(G(z))||\mathrm{fake\ tag})
\]
其中 \(D_{\mathrm{score}}\) 是输出真伪概率的判别器,\(D_{\mathrm{tag}}\) 是输出分类信息的分类判别器,\(CE\) 是交叉熵损失,分类任务的标配。在实现上,可以共用一个特征提取的骨干网络,替换不同维度的投影头即可。
下面看看代码:
AC-GAN 的初版训练代码
| import random
import contextlib
import numpy as np
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as T
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
# -------------------
# Configs & utils
# -------------------
seed = 3407
random.seed(seed); np.random.seed(seed); torch.manual_seed(seed)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# cuDNN 加速
cudnn.enabled = True
cudnn.benchmark = True
# 显式禁用 TF32(P100 不支持;此设置在 P100 上为 no-op)
try:
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
except Exception:
pass
# Hyper-params
num_classes = 10
image_size = 32
z_dim = 128
g_embed_dim = 128
batch_size = 256
lr = 2e-4
beta1, beta2 = 0.5, 0.999
num_epochs = 250
use_amp = (device.type == 'cuda') # P100 支持 FP16(无 TensorCores)
use_channels_last = (device.type == 'cuda')
real_label_smooth = 0.9
# Data transforms: 无训练增广;仅归一化到 [-1, 1]
mean = (0.5, 0.5, 0.5)
std = (0.5, 0.5, 0.5)
train_tfms = T.Compose([
T.ToTensor(),
T.Normalize(mean, std),
])
test_tfms = T.Compose([
T.ToTensor(),
T.Normalize(mean, std),
])
# Datasets & Dataloaders
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=train_tfms)
test_set = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=test_tfms)
loader_kwargs = dict(
batch_size=batch_size,
num_workers=6,
pin_memory=True,
persistent_workers=True, # 若在 notebook 反复运行报错,可改为 False
prefetch_factor=4,
)
train_loader = DataLoader(train_set, shuffle=True, drop_last=True, **loader_kwargs)
test_loader = DataLoader(test_set, shuffle=False, drop_last=False, **loader_kwargs)
classes = train_set.classes
# AMP autocast context
amp_ctx = torch.autocast(device_type='cuda', dtype=torch.float16) if use_amp else contextlib.nullcontext()
def denorm(x):
# [-1, 1] -> [0, 1]
return (x * 0.5 + 0.5).clamp(0, 1)
# -------------------
# Models
# -------------------
class Generator(nn.Module):
def __init__(self, z_dim=128, num_classes=10, embed_dim=100, base_ch=256):
super().__init__()
self.embed = nn.Embedding(num_classes, embed_dim)
self.fc = nn.Linear(z_dim + embed_dim, 4 * 4 * base_ch)
self.net = nn.Sequential(
nn.BatchNorm2d(base_ch),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(base_ch, base_ch // 2, 4, 2, 1, bias=False), # 8x8
nn.BatchNorm2d(base_ch // 2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(base_ch // 2, base_ch // 4, 4, 2, 1, bias=False), # 16x16
nn.BatchNorm2d(base_ch // 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(base_ch // 4, base_ch // 8, 4, 2, 1, bias=False), # 32x32
nn.BatchNorm2d(base_ch // 8),
nn.ReLU(inplace=True),
nn.Conv2d(base_ch // 8, 3, 3, 1, 1),
nn.Tanh()
)
def forward(self, z, y):
e = self.embed(y)
h = torch.cat([z, e], dim=1)
h = self.fc(h)
# 用 reshape(兼容 channels_last / 非连续内存)
h = h.reshape(h.size(0), -1, 4, 4)
return self.net(h)
class Discriminator(nn.Module):
def __init__(self, num_classes=10, base_ch=64):
super().__init__()
sn = nn.utils.spectral_norm # 稳定训练
self.features = nn.Sequential(
sn(nn.Conv2d(3, base_ch, 4, 2, 1, bias=False)), # 16x16
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(base_ch, base_ch * 2, 4, 2, 1, bias=False)), # 8x8
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(base_ch * 2, base_ch * 4, 4, 2, 1, bias=False)), # 4x4
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(base_ch * 4, base_ch * 8, 4, 2, 1, bias=False)), # 2x2
nn.LeakyReLU(0.2, inplace=True),
)
self.flatten_dim = base_ch * 8 * 2 * 2
self.src_head = sn(nn.Linear(self.flatten_dim, 1)) # real/fake
self.cls_head = sn(nn.Linear(self.flatten_dim, num_classes)) # class logits
def forward(self, x):
h = self.features(x)
# 用 flatten(兼容 channels_last)
h = torch.flatten(h, 1)
src = self.src_head(h)
cls = self.cls_head(h)
return src, cls
def weights_init(m):
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.Linear)):
if getattr(m, 'weight', None) is not None:
nn.init.normal_(m.weight, 0.0, 0.02)
if getattr(m, 'bias', None) is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.normal_(m.weight, 1.0, 0.02)
nn.init.zeros_(m.bias)
G = Generator(z_dim, num_classes, g_embed_dim).to(device)
D = Discriminator(num_classes).to(device)
if use_channels_last:
G = G.to(memory_format=torch.channels_last)
D = D.to(memory_format=torch.channels_last)
G.apply(weights_init)
D.apply(weights_init)
# -------------------
# Optimizers & Losses
# -------------------
opt_G = torch.optim.Adam(G.parameters(), lr=lr, betas=(beta1, beta2))
opt_D = torch.optim.Adam(D.parameters(), lr=lr, betas=(beta1, beta2))
bce = nn.BCEWithLogitsLoss()
ce = nn.CrossEntropyLoss()
scaler_G = torch.cuda.amp.GradScaler(enabled=use_amp)
scaler_D = torch.cuda.amp.GradScaler(enabled=use_amp)
# -------------------
# Eval: classifier accuracy on test set
# -------------------
@torch.no_grad()
def eval_test_accuracy():
D.eval()
total, correct = 0, 0
for x, y in test_loader:
x = x.to(device, non_blocking=True)
if use_channels_last:
x = x.to(memory_format=torch.channels_last)
y = y.to(device, non_blocking=True)
with amp_ctx:
_, logits = D(x)
pred = logits.argmax(dim=1)
correct += (pred == y).sum().item()
total += y.size(0)
acc = 100.0 * correct / total
return acc
# -------------------
# Training loop
# -------------------
def train():
G.train(); D.train()
hist_loss_D, hist_loss_G, hist_acc = [], [], []
for epoch in range(1, num_epochs + 1):
pbar = tqdm(train_loader, desc=f'Epoch {epoch}/{num_epochs}', leave=True)
running_D, running_G = 0.0, 0.0
for i, (x_real, y_real) in enumerate(pbar):
x_real = x_real.to(device, non_blocking=True)
if use_channels_last:
x_real = x_real.to(memory_format=torch.channels_last)
y_real = y_real.to(device, non_blocking=True)
bsz = x_real.size(0)
valid = torch.full((bsz, 1), real_label_smooth, device=device)
fake = torch.zeros(bsz, 1, device=device)
# -----------------
# Train Discriminator
# -----------------
z = torch.randn(bsz, z_dim, device=device)
y_fake = torch.randint(0, num_classes, (bsz,), device=device)
with amp_ctx:
x_fake = G(z, y_fake).detach()
d_src_real, d_cls_real = D(x_real)
d_src_fake, d_cls_fake = D(x_fake)
d_loss_real = bce(d_src_real, valid) + ce(d_cls_real, y_real)
d_loss_fake = bce(d_src_fake, fake) + ce(d_cls_fake, y_fake)
d_loss = d_loss_real + d_loss_fake
opt_D.zero_grad(set_to_none=True)
scaler_D.scale(d_loss).backward()
scaler_D.step(opt_D)
scaler_D.update()
# -----------------
# Train Generator
# -----------------
z = torch.randn(bsz, z_dim, device=device)
y_fake = torch.randint(0, num_classes, (bsz,), device=device)
with amp_ctx:
gen = G(z, y_fake)
g_src, g_cls = D(gen)
g_loss = bce(g_src, valid) + ce(g_cls, y_fake)
opt_G.zero_grad(set_to_none=True)
scaler_G.scale(g_loss).backward()
scaler_G.step(opt_G)
scaler_G.update()
running_D += d_loss.item()
running_G += g_loss.item()
if (i + 1) % 10 == 0:
pbar.set_postfix({
'loss_D': f'{running_D / (i + 1):.4f}',
'loss_G': f'{running_G / (i + 1):.4f}'
})
# epoch 平均损失
epoch_loss_D = running_D / len(train_loader)
epoch_loss_G = running_G / len(train_loader)
hist_loss_D.append(epoch_loss_D)
hist_loss_G.append(epoch_loss_G)
# 评估测试集准确率(判别器的辅助分类头)
acc = eval_test_accuracy()
hist_acc.append(acc)
print(f'[Epoch {epoch}] loss_D={epoch_loss_D:.4f} loss_G={epoch_loss_G:.4f} | Test Acc={acc:.2f}%')
# 继续训练模式
D.train(); G.train()
return hist_loss_D, hist_loss_G, hist_acc
# -------------------
# Plot: 损失曲线 + 准确率曲线
# -------------------
def plot_history(loss_D, loss_G, acc):
epochs = range(1, len(loss_D) + 1)
plt.figure(figsize=(12, 4))
# 损失
plt.subplot(1, 2, 1)
plt.plot(epochs, loss_D, label='D loss')
plt.plot(epochs, loss_G, label='G loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('AC-GAN Training Loss')
plt.legend()
plt.grid(True, alpha=0.3)
# 准确率
plt.subplot(1, 2, 2)
plt.plot(epochs, acc, color='tab:green', label='Test Acc (%)')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Aux Classifier Test Accuracy')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# -------------------
# Generate: 10 classes, 5 images each, grid 10x5
# -------------------
@torch.no_grad()
def generate_grid_horizontal_labeled(n_per=5):
G.eval()
imgs_by_class = []
for c in range(num_classes):
z = torch.randn(n_per, z_dim, device=device)
y = torch.full((n_per,), c, dtype=torch.long, device=device)
# 关闭 autocast 或显示前转 float32,避免 matplotlib 不支持 float16
with torch.autocast(device_type='cuda', enabled=False) if use_amp else contextlib.nullcontext():
x = G(z, y)
imgs_by_class.append(x.detach().cpu().float()) # [n_per, 3, 32, 32]
# 画成 5 行 × 10 列
fig, axes = plt.subplots(n_per, num_classes, figsize=(num_classes * 1.8, n_per * 1.8))
if n_per == 1:
axes = np.expand_dims(axes, 0) # 兼容 n_per=1 的索引
for col in range(num_classes):
# 顶部列标题(类别名)
axes[0, col].set_title(classes[col], fontsize=10)
for row in range(n_per):
img = denorm(imgs_by_class[col][row]).permute(1, 2, 0).numpy() # HWC float32
ax = axes[row, col]
ax.imshow(img)
ax.axis('off')
plt.tight_layout(w_pad=0.1, h_pad=0.1)
plt.show()
# -------------------
# Run
# -------------------
loss_D_hist, loss_G_hist, acc_hist = train()
plot_history(loss_D_hist, loss_G_hist, acc_hist)
generate_grid_horizontal_labeled()
|


虽然准确率最终稳定在了 66% 左右,但是可见出现了一个很大的问题。虽然 loss 一直很稳没有炸,但是同一类别下,不同种子生成的图像全都一个样。
这意味着出现了模式崩塌,其实问题还是出在结构上面:生成器得到的梯度完全是从判别器回传得到的,这就说明我的生成器可以偷个懒,只打磨那么一个可以骗过判别器的输出,然后就可以专心去应对分类损失项了,这其实有点 reward hacking 的味道了,因此我们还需要加入一个改进,强迫生成器生成更多样化的样本。
对样本的多样化程度该如何衡量?从统计学意义上讲,使用标准差即可。也就是说,我们可以将这个 batch 里面的所有样本计算一个标准差,再拼接到特征图后面。这样,判别器就可以根据这一线索来对生成器的偷懒行为做出反应。这个叫做 Mini-Batch StdDev 策略。另一方面,我们可以在训练一开始对样本加入少量噪声,这样一开始就可以强迫生成器输出更多样的内容(熵更高),后面再衰减。
结合上之前稳定训练的 TTUR 和谱归一化,我们就可以写出下面的代码了:
训练 AC-GAN 的代码
| import random
import contextlib
import numpy as np
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
import torchvision
import torchvision.transforms as T
from torchvision.utils import make_grid
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
# -------------------
# Configs & utils
# -------------------
seed = 3407
random.seed(seed); np.random.seed(seed); torch.manual_seed(seed)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# cuDNN 加速
cudnn.enabled = True
cudnn.benchmark = True
# 显式禁用 TF32
try:
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
except Exception:
pass
# Hyper-params
num_classes = 10
image_size = 32
z_dim = 128
g_embed_dim = 128
batch_size = 256
beta1, beta2 = 0.5, 0.999
num_epochs = 250
use_amp = (device.type == 'cuda')
use_channels_last = (device.type == 'cuda')
# 抑制模式崩塌的关键超参
real_label_smooth = 0.9
lambda_cls = 0.5 # 分类损失权重(AC-GAN 的 CE)
lr_G, lr_D = 1e-4, 2e-4 # TTUR
inst_noise_start = 0.1 # instance noise 初始标准差
inst_noise_stop_frac = 0.5 # 在前 50% epoch 线性衰减到 0
# Data transforms: 无训练增广;仅归一化到 [-1, 1]
mean = (0.5, 0.5, 0.5)
std = (0.5, 0.5, 0.5)
train_tfms = T.Compose([
T.ToTensor(),
T.Normalize(mean, std),
])
test_tfms = T.Compose([
T.ToTensor(),
T.Normalize(mean, std),
])
# Datasets & Dataloaders
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=train_tfms)
test_set = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=test_tfms)
loader_kwargs = dict(
batch_size=batch_size,
num_workers=6,
pin_memory=True,
persistent_workers=True, # 若在 notebook 反复运行报错,可改为 False
prefetch_factor=4,
)
train_loader = DataLoader(train_set, shuffle=True, drop_last=True, **loader_kwargs)
test_loader = DataLoader(test_set, shuffle=False, drop_last=False, **loader_kwargs)
classes = train_set.classes
# AMP autocast context
amp_ctx = torch.autocast(device_type='cuda', dtype=torch.float16) if use_amp else contextlib.nullcontext()
def denorm(x):
# [-1, 1] -> [0, 1]
return (x * 0.5 + 0.5).clamp(0, 1)
# 训练用:在 D 输入侧加入 Instance Noise
def add_instance_noise(x, epoch, num_epochs, start_std=0.1, stop_frac=0.5):
stop_epoch = int(num_epochs * stop_frac)
if epoch > stop_epoch or start_std <= 0:
return x
# 线性衰减
t = epoch / max(1, stop_epoch)
std = start_std * (1.0 - t)
noise = torch.randn_like(x) * std
return (x + noise).clamp(-1, 1)
# -------------------
# Models
# -------------------
class Generator(nn.Module):
def __init__(self, z_dim=128, num_classes=10, embed_dim=128, base_ch=256):
super().__init__()
self.embed = nn.Embedding(num_classes, embed_dim)
self.fc = nn.Linear(z_dim + embed_dim, 4 * 4 * base_ch)
self.net = nn.Sequential(
nn.BatchNorm2d(base_ch),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(base_ch, base_ch // 2, 4, 2, 1, bias=False), # 8x8
nn.BatchNorm2d(base_ch // 2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(base_ch // 2, base_ch // 4, 4, 2, 1, bias=False), # 16x16
nn.BatchNorm2d(base_ch // 4),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(base_ch // 4, base_ch // 8, 4, 2, 1, bias=False), # 32x32
nn.BatchNorm2d(base_ch // 8),
nn.ReLU(inplace=True),
nn.Conv2d(base_ch // 8, 3, 3, 1, 1),
nn.Tanh()
)
def forward(self, z, y):
e = self.embed(y)
h = torch.cat([z, e], dim=1)
h = self.fc(h)
h = h.reshape(h.size(0), -1, 4, 4) # 兼容 channels_last
return self.net(h)
class MinibatchStdDev(nn.Module):
def __init__(self, eps=1e-8):
super().__init__()
self.eps = eps
def forward(self, x):
# 计算批内标准差的均值,作为1个额外通道
# x: [N, C, H, W]
std = torch.sqrt(x.var(dim=0, unbiased=False) + self.eps) # [C, H, W]
mean_std = std.mean().view(1, 1, 1, 1).expand(x.size(0), 1, x.size(2), x.size(3))
return torch.cat([x, mean_std], dim=1)
class Discriminator(nn.Module):
def __init__(self, num_classes=10, base_ch=64):
super().__init__()
sn = nn.utils.spectral_norm # 稳定训练
self.features = nn.Sequential(
sn(nn.Conv2d(3, base_ch, 4, 2, 1, bias=False)), # 16x16
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(base_ch, base_ch * 2, 4, 2, 1, bias=False)), # 8x8
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(base_ch * 2, base_ch * 4, 4, 2, 1, bias=False)), # 4x4
nn.LeakyReLU(0.2, inplace=True),
sn(nn.Conv2d(base_ch * 4, base_ch * 8, 4, 2, 1, bias=False)), # 2x2
nn.LeakyReLU(0.2, inplace=True),
MinibatchStdDev(), # +1 通道
)
self.flatten_dim = (base_ch * 8 + 1) * 2 * 2
self.src_head = sn(nn.Linear(self.flatten_dim, 1)) # real/fake
self.cls_head = sn(nn.Linear(self.flatten_dim, num_classes)) # class logits
def forward(self, x):
h = self.features(x)
h = torch.flatten(h, 1) # 兼容 channels_last
src = self.src_head(h)
cls = self.cls_head(h)
return src, cls
def weights_init(m):
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.Linear)):
if getattr(m, 'weight', None) is not None:
nn.init.normal_(m.weight, 0.0, 0.02)
if getattr(m, 'bias', None) is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.normal_(m.weight, 1.0, 0.02)
nn.init.zeros_(m.bias)
G = Generator(z_dim, num_classes, g_embed_dim).to(device)
D = Discriminator(num_classes).to(device)
if use_channels_last:
G = G.to(memory_format=torch.channels_last)
D = D.to(memory_format=torch.channels_last)
G.apply(weights_init)
D.apply(weights_init)
# -------------------
# Optimizers & Losses
# -------------------
opt_G = torch.optim.Adam(G.parameters(), lr=lr_G, betas=(beta1, beta2)) # TTUR
opt_D = torch.optim.Adam(D.parameters(), lr=lr_D, betas=(beta1, beta2))
bce = nn.BCEWithLogitsLoss()
ce = nn.CrossEntropyLoss()
scaler_G = torch.cuda.amp.GradScaler(enabled=use_amp)
scaler_D = torch.cuda.amp.GradScaler(enabled=use_amp)
# -------------------
# Eval: classifier accuracy on test set
# -------------------
@torch.no_grad()
def eval_test_accuracy():
D.eval()
total, correct = 0, 0
for x, y in test_loader:
x = x.to(device, non_blocking=True)
if use_channels_last:
x = x.to(memory_format=torch.channels_last)
y = y.to(device, non_blocking=True)
with amp_ctx:
_, logits = D(x) # 评估时不加噪声
pred = logits.argmax(dim=1)
correct += (pred == y).sum().item()
total += y.size(0)
acc = 100.0 * correct / total
return acc
# -------------------
# Training loop
# -------------------
def train():
G.train(); D.train()
hist_loss_D, hist_loss_G, hist_acc = [], [], []
for epoch in range(1, num_epochs + 1):
pbar = tqdm(train_loader, desc=f'Epoch {epoch}/{num_epochs}', leave=True)
running_D, running_G = 0.0, 0.0
for i, (x_real, y_real) in enumerate(pbar):
x_real = x_real.to(device, non_blocking=True)
if use_channels_last:
x_real = x_real.to(memory_format=torch.channels_last)
y_real = y_real.to(device, non_blocking=True)
bsz = x_real.size(0)
valid = torch.full((bsz, 1), real_label_smooth, device=device)
fake = torch.zeros(bsz, 1, device=device)
# -----------------
# Train Discriminator
# -----------------
z = torch.randn(bsz, z_dim, device=device)
y_fake = torch.randint(0, num_classes, (bsz,), device=device)
with amp_ctx:
x_fake = G(z, y_fake).detach()
# Instance noise(仅训练使用)
x_real_in = add_instance_noise(x_real, epoch, num_epochs, inst_noise_start, inst_noise_stop_frac)
x_fake_in = add_instance_noise(x_fake, epoch, num_epochs, inst_noise_start, inst_noise_stop_frac)
d_src_real, d_cls_real = D(x_real_in)
d_src_fake, d_cls_fake = D(x_fake_in)
d_loss_real = bce(d_src_real, valid) + lambda_cls * ce(d_cls_real, y_real)
d_loss_fake = bce(d_src_fake, fake) + lambda_cls * ce(d_cls_fake, y_fake)
d_loss = d_loss_real + d_loss_fake
opt_D.zero_grad(set_to_none=True)
scaler_D.scale(d_loss).backward()
scaler_D.step(opt_D)
scaler_D.update()
# -----------------
# Train Generator
# -----------------
z = torch.randn(bsz, z_dim, device=device)
y_fake = torch.randint(0, num_classes, (bsz,), device=device)
with amp_ctx:
gen = G(z, y_fake)
# G 反传路径也加同样的 instance noise
gen_in = add_instance_noise(gen, epoch, num_epochs, inst_noise_start, inst_noise_stop_frac)
g_src, g_cls = D(gen_in)
g_loss = bce(g_src, valid) + lambda_cls * ce(g_cls, y_fake)
opt_G.zero_grad(set_to_none=True)
scaler_G.scale(g_loss).backward()
scaler_G.step(opt_G)
scaler_G.update()
running_D += d_loss.item()
running_G += g_loss.item()
if (i + 1) % 10 == 0:
pbar.set_postfix({
'loss_D': f'{running_D / (i + 1):.4f}',
'loss_G': f'{running_G / (i + 1):.4f}'
})
# epoch 平均损失
epoch_loss_D = running_D / len(train_loader)
epoch_loss_G = running_G / len(train_loader)
hist_loss_D.append(epoch_loss_D)
hist_loss_G.append(epoch_loss_G)
# 评估测试集准确率(判别器的辅助分类头)
acc = eval_test_accuracy()
hist_acc.append(acc)
print(f'[Epoch {epoch}] loss_D={epoch_loss_D:.4f} loss_G={epoch_loss_G:.4f} | Test Acc={acc:.2f}%')
# 继续训练模式
D.train(); G.train()
return hist_loss_D, hist_loss_G, hist_acc
# -------------------
# Plot: 损失曲线 + 准确率曲线
# -------------------
def plot_history(loss_D, loss_G, acc):
epochs = range(1, len(loss_D) + 1)
plt.figure(figsize=(12, 4))
# 损失
plt.subplot(1, 2, 1)
plt.plot(epochs, loss_D, label='D loss')
plt.plot(epochs, loss_G, label='G loss')
plt.xlabel('Epoch'); plt.ylabel('Loss'); plt.title('AC-GAN Training Loss')
plt.legend(); plt.grid(True, alpha=0.3)
# 准确率
plt.subplot(1, 2, 2)
plt.plot(epochs, acc, color='tab:green', label='Test Acc (%)')
plt.xlabel('Epoch'); plt.ylabel('Accuracy (%)'); plt.title('Aux Classifier Test Accuracy')
plt.legend(); plt.grid(True, alpha=0.3)
plt.tight_layout(); plt.show()
# -------------------
# Generate: 横向 10 类 × 每类 5 张,列顶显示标签
# -------------------
@torch.no_grad()
def generate_grid_horizontal_labeled(n_per=5):
G.eval()
imgs_by_class = []
for c in range(num_classes):
z = torch.randn(n_per, z_dim, device=device)
y = torch.full((n_per,), c, dtype=torch.long, device=device)
# 关闭 autocast 或显示前转 float32,避免 matplotlib 不支持 float16
with torch.autocast(device_type='cuda', enabled=False) if use_amp else contextlib.nullcontext():
x = G(z, y)
imgs_by_class.append(x.detach().cpu().float()) # [n_per, 3, 32, 32]
fig, axes = plt.subplots(n_per, num_classes, figsize=(num_classes * 1.8, n_per * 1.8))
if n_per == 1:
axes = np.expand_dims(axes, 0)
for col in range(num_classes):
axes[0, col].set_title(classes[col], fontsize=10)
for row in range(n_per):
img = denorm(imgs_by_class[col][row]).permute(1, 2, 0).numpy()
ax = axes[row, col]
ax.imshow(img)
ax.axis('off')
plt.tight_layout(w_pad=0.1, h_pad=0.1)
plt.show()
# -------------------
# Run
# -------------------
loss_D_hist, loss_G_hist, acc_hist = train()
plot_history(loss_D_hist, loss_G_hist, acc_hist)
generate_grid_horizontal_labeled()
|
可以看到,模型训练相当稳定,准确率也比之前高了一些,达到了 69% 的水准。

生成的图像里面,也有很多是挺像模像样的。

总结
通过本次对多个经典及探索性模型的复现之旅,我们从最基础的 MLP 一路走到复杂的生成式网络,不仅观察了它们在 CIFAR-10 数据集上的性能差异,更深入体会了其设计哲学背后的演变逻辑。这些实验告诉我们,模型的选择绝非简单的性能排行榜,而是一场在精度、效率、数据依赖性和架构复杂性之间的多维权衡。
最初的 MLP 像是一把万能钥匙,试图用巨量的参数强行拟合所有问题,但它忽略了图像最基本的空间结构信息,效率低下,最终结果也难尽如人意。CNN 的引入是一个革命性的突破,它通过卷积、池化等操作巧妙地注入了“平移不变性”和“局部性”的先验知识,使得网络能够更高效地捕捉图像特征。我们的复现也印证了这一点,一个参数量更少的简单 CNN 取得了远优于 MLP 的效果。而 ResNet 及其残差连接则进一步解决了深层网络的梯度传递难题,让网络能够向更深、更强大的方向发展,成为此后多年来的中流砥柱。
Transformer 的出现改变了游戏规则。ViT 将图像拆分为 Patch,并利用自注意力机制进行全局建模,这种“无先验”的设计使其在大规模数据上展现了惊人的 Scaling Law。我们的实验清晰展示了这一点:在小规模从头训练的 nanoViT 表现平平,但其大型预训练版本(ViT-B)通过微调便能达到惊人的性能,这揭示了“预训练+微调”范式在当今 AI 领域的绝对统治力。
而那些“邪门”的探索,如 PatchLSTM、VAE 和 AC-GAN,则从另一个维度拓展了我们的视野。它们证明了图像的表示和学习方式可以多种多样——无论是用序列模型处理,还是通过学习数据分布本身来获得强大的特征表示。特别是将 VAE 作为正则化器与分类器联合训练的思路,在数据稀缺的场景下显示出独特的价值。
为了更直观地对比,我们将本次复现的核心结果归纳如下表:
| 模型 |
参数量 |
测试准确率 |
特点与适用场景 |
| MLP |
~1.7M |
54.44% |
基线模型,忽略空间结构,效率低,仅用于教学和理解。 |
| CNN |
~1.1M |
77.33% |
架构高效,引入局部性与平移不变性先验,精度与速度的良好平衡。 |
| ResNet-18 (从零训练) |
~11.2M |
83.46% |
深层网络典范,残差连接解决梯度问题,通用性强。 |
| ResNet-18 (微调) |
~11.2M |
89.06% |
预训练+微调范式的体现,利用迁移学习获得优异性能。 |
| nanoViT (从零训练) |
~1.2M |
73.24% |
数据不足时易过拟合,但展现了全局建模的潜力。 |
| ViT-B/16 (微调) |
>86M |
95.42% |
大数据预训练力量的证明,当前 SOTA 的代表,精度天花板高。 |
| PatchLSTM |
~2.5M |
68.11% |
将图像视为序列的探索性尝试,性能通常不如CNN,效率较低。 |
| VAE (无监督聚类) |
- |
~24% |
验证了隐空间特征的有效性,但无监督分类与语义标签有天然差距。 |
| VAE + 分类头 |
- |
~82% |
生成式损失作为正则项,在数据稀缺时是提升泛化的有效手段。 |
| AC-GAN |
- |
~69% |
兼具生成与分类能力,适用于半监督学习和需要生成能力的场景。 |
纵观上表,我们可以得出更贴近实践的结论:
- 若追求极致精度且资源充足:大规模预训练模型(如 ViT, ResNet)微调是毋庸置疑的首选,这是当前应用和研究的主流。
- 若需从零开始训练:CNN 及它的现代变体(如 ResNet 等) 仍然是稳健和高效的选择,在精度、速度和可靠性之间取得了最佳平衡。
- 若面临数据稀缺的挑战:生成式模型(如 VAE 和 GAN) 提供了一条不同的思路。将其作为特征提取器或正则化器与分类任务联合训练,往往能通过利用数据本身分布来提升模型泛化能力。
- 若进行模型探索与研究:Transformer、基于序列的模型乃至生成对抗网络,为我们打开了新的可能性,但它们通常需要更多的数据、调优技巧和计算资源,也面临未知的性能上限和更具挑战性的过程。
本文是复现笔记系列的第一篇。图像分类很简单也很经典,但也催生了诸多高效的模型。希望本篇文章的复现经历与对比分析,能为各位看官的选择提供一份有价值的参考。作者功力尚陋,不足之处请在下方评论区批评指正,切磋交流。感谢您的阅读。